On 'Information' in Organizations:
An Emergent Information Theory and Semiotic Framework
Kevin C. Desouza
University of Illinois, USA
Tobin Hensgen
Loyola University of Chicago, USA
Introduction
Academics and practitioners alike have a tendency to overuse, perhaps misuse, the term “information.” We become accustomed to seeing such phrases as “information economy,” “information systems,” “information society,” and “information management” in myriad applications. Subsequently, the concept of information to a large extent becomes diluted and tends to serve as rhetoric rather than as an analytical or insightful function (Newman, 2001). For systems researchers, the term becomes a conundrum, inside of a puzzle, surrounded by a riddle with a meaning entirely lost to the realm of etymology. Under such conditions it has been noted that representation and reality can become so disparate that because of limits in language there may develop a corresponding limit in thought (Wittgenstein, 1953). In a world where everything is immediately regarded as information the word itself loses value, and being without value severely restricts the motivation for purposeful research. In a sense, this notion revisits Hardin's tragedy of the commons in which the pasture is open to all but the motive of self-interest results in overgrazing until the saturated resource is lost to everyone (Hardin, 1968).
For information to be useful it must be necessary; to be necessary it must be universal in the way that a mathematical expression written by an Englishman can be understood and interpreted by a mathematician in China. Here, understanding is derived from the mapping of symbols common to both participants despite the fact that other aspects of culture or language may be different. In such instances, the syntax of the mathematical expression is organized from data “in reality” rather than allowing any single definition “of reality” to imprint itself on the data.1 Current system literature provides little that addresses what is necessary or why there is a requirement for universality in information. To accomplish this task a prescriptive model that explains these roles must be used to reflect information comprehension as well as its role in causation leading to an actionable event. Models such as Simon's intelligence-design-choice-implementation, while important, do not focus explicitly on the semiotics associated with information flow and how it succeeds a phase associated with the broader sense of intelligence (Simon, 1960).
The objectives of this article are twofold. First, we hope to provide a succinct and novel focus on the idea of “information as necessary,” with the aim being to clear some common misconceptions. Secondly, we want to offer an understanding of some of the common economics related to governing dynamics on how “universal information” moves not merely through, but beyond, organizational boundaries.
INFORMATION THEORY
Communication is simple: merely bridge the gap between what is intended and what is interpreted. But what happens if, while crossing that bridge, a big gust of wind comes along and your intended message, which has been collected in orderly sheets as “information,” starts blowing all over the place? Your first reaction is to try to seize all the sheets, but the wind picks up and you begin to fear for your safety. Now you collect what you can, forsake the rest, and focus on completing your journey to the other side where you deliver your message. However, the message is now in disarray and your concern is not what has been delivered but what is missing. Similarly, the message recipient was expecting a specific solution from among the pages and is uncertain if what you have delivered will provide an answer. The question remains: Was information delivered? The answer, of course, is yes and no. The effectiveness of your conveyance will be determined not by the sheets labeled “information” that have been delivered but by the level of uncertainty of the interpreter that has been reduced.
Drawing on the work of scholars from communication theory helps us analyze the value of what made it across the bridge. Claude Shannon's research in the 1940s in information theory introduced a simple abstraction of communication, called the channel, which carries the message within a signal between the sender (information source) and the receiver (information destination). Shannon's communication model suggested, among other things, that the channel, the medium used to transmit—like our bridge—was subject to noise and distortion—again like our gust of wind. Here, noise is anything that corrupts the integrity of the message.
Shannon's work led to a solid mathematical basis that underpins today's understanding of communication patterns and behaviors in both digital and analog settings. He argued that information is conveyed when the message changes the receiver's knowledge. This may only occur if the receiver is in a state of qualified uncertainty, to the extent that the information in a message is not predictable or is already known. Nothing new can be created where everything is necessary and nothing is uncertain; where everything is certain there is no need for information, nor is there any incentive for seeking new information (Campbell, 1982). The hubris in Polaroid's failure to understand the implications of digital photography demonstrates how this idea can backfire. Failures in information are often associated with instances where internal consistency is valued more highly than efficiency (Dickson, 1978).
To better understand the relation between the certainty of the message and the uncertainty provided amid the noise of the channel, Shannon borrowed from physics' second law of thermodynamics and employed the term entropy, which refers to the measure of uncertainty in any given system. The reduction in uncertainty (high entropy) associated with the message-event may be interpreted as information (low entropy). It should be mentioned the context of the information, that is meaning (semantics), is irrelevant at this stage (Shannon, 1963). Thus we posit that only when an element transmits data that diminishes uncertainty, as perceived by the sender, do we have information of value.
SEMIOTICS
Sanders Pierce (1829-1914), a mathematician and logician, founded the field of semiotics, which represents information flow from data capture through to some actionable event, for example decision making (Andersen, 1991; Clarke et al., 2001; Liu, 2000; Lyons, 1977; Watzlawick et al., 1967). The domain of semiotics can be broken down into three distinct sections: syntactics, which deals with relationships or linkages between various components; semantics, which is concerned with putting the relationships in context; and pragmatics, which deduces meaning or insights from relationships in context.
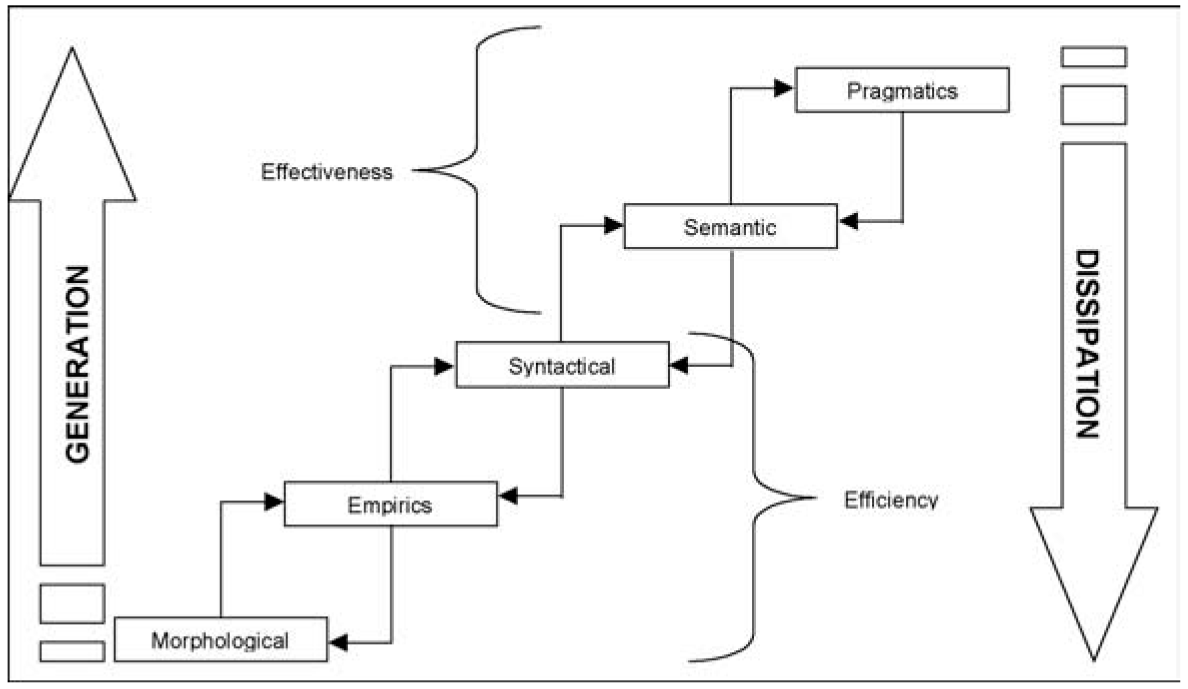
Figure 1 The evolutionary perspective of information
Here we first approach the condition of meaning that was not addressed by Shannon, since he was more concerned with technical rather than semantic problems in communication. We can understand the semiotic flow of information using an evolutionary approach as proposed by Desouza and Ramaprasad (see Figure 1).2 In this realm, we see the upward movement of generation: from gathering data on the various entities of the organization, followed by calculating empirics of the data, to drawing syntactical connections among these disparate pieces leading to informational value. The flow is then affected by semantics en route to its aspirations of pragmatic insights or knowledge. The process is, in practice, bidirectional.
We can also move down the other side of the evolutionary path, that is the dissipation path of knowledge, during which we begin with conceptualizing relevant actions that need to be carried out, based on the revelations of pragmatic insight. This is followed by explaining the model's rationale to the various stakeholders in the organizations. Next, we translate this logical thought into an actionable physical task intended, finally, to modify the behavior of agents or objects at the morphological level.
THE PROCESS
At the morphological (physical) level we are concerned with agents and objects of interest to the organization. These are collectively known as sources of information (SOI—Desouza, 2001; Maes, 1995; Ramaprasad & Rai, 1996). A wide assortment of sources can be found, including agents or objects within the control of the organization such as its manufacturing or human resource systems, those that are owned by its partners, such as suppliers or contained in inventory systems, or those that belong to the external environment at large, such as found in publications and so on.
Data collected can be in a variety of forms, such as what might be associated with the five senses and intuition, or it might arrive through channels more often associated with formal routes, such as data from transaction systems, or informal routes like employee discussions and brainstorming sessions. At the morphological level an organization clearly identifies the sources, type, and characteristics of the data it has at its disposal. It is here that we have an inordinate variety of information sources.
The next level of the semiotic chain is empiric. Here we aggregate like sources into manageable chunks. Empirics are concerned with studying statistical properties of objects from the morphological level. Common tasks at the empirical level involve validation and processing. At the validation stage, judgments need to be made as to the legitimacy of the data gathered, how much significance a particular data element should be given, and whether the data needs to be “cleaned” or further processed.
The first phase is validation or error checking. This involves making sure that data elements have the correct standards of association assigned to them. For example, when designing a database, although symbols associated with integers occur in the representation of telephone numbers, zip codes, or social security numbers, they are entered as alpha characters because they will never be used in a mathematical context; one would never add zip codes together. This practice helps to normalize the database and ensures that the data will be represented along the lines of an associated, recognizable standard. Once data elements are validated, they are ready for processing. A key task in the processing of data elements is summarization.
The level of summarization will vary depending on organizational needs and system design (Desouza, 2002, 2003). The higher the level of summarization, the less detail we have on individual transactions. The lower the level of summarization, the more detail we have; eventually every transaction will be summarized. At this stage, the value of processed data in summarization does not necessarily relate to the level of detail; rather, summarization makes data objects manageable. The disparate pieces may now be connected at the syntactical level of our model. It is here in our evolutionary scheme that we begin to derive more complex, higher-order objects by assimilating and linking otherwise incongruent data items.
At this level, our primary concern is structuring data items into meaningful sets. Common tasks include ensuring referential integrity and defining relationships according to some grammar or code. Referential integrity requires us to remove the inconsistencies among data stores. Weighted probabilities are one method of establishing the required grammar or code. Failure to ensure referential integrity may result in the construction of duplicate sequences that add time to analysis and, more importantly, can be wrong in that they create a potential for anomalies. Defining relationships among the data items is the next crucial task of this phase. One needs to have clearly defined rules or syntax prior to carrying this out. One approach to structuring data involves the use of devices such as triggers, enhancers, and suppressors (Dalmadge, 2000).
Triggers can be defined as the first wave of symptoms or signs leading to an impending event. Shrivastava (1987) defines them as “a specific event that is identifiable in time and place and traceable to specific manmade causes.” We include natural causes in our definition. Enhancers are factors or events that increase the sensitivity of a trigger, either by increasing the magnitude of its effects, or by speeding the time taken for the event to occur. Suppressors have the opposite effect and work to curtail the events of the trigger. At the empirical level of our model, we have sets of processed data objects, which may be viewed as triggers. Using our syntax, we identify linkages between data objects by deducing items that either enhance or suppress the value of each object.
Other approaches to developing syntactics include cause-effect diagrams, association rules, network analysis, and so on. Following the deduction of syntactics, we require the encapsulation of data sets based on an assumption of “reality” or context. The semantic levels help in defining the tasks of this objective through careful analysis of the components of the informational relationship in the appropriate context. This calls for studying the component objects in their relationship, their association, and the role that the environment or context plays in regards to the association.
The context in which the relationship is viewed plays a crucial role in interpretation. We can have either static or dynamic components in the relationship. Static represents nonchanging conditions or environments in which the occurrences of relationships have the same outcome regardless of timing. Dynamic contexts, on the other hand, are more common among today's environmental conditions. Here, the temporal component of the relationship plays a major role. Without a “plan” the effects of entropy soon become evident, as “dated information” may decline in relevance simply because of timing!
Once the context of a relationship is identified, we are ready to extrapolate insights (knowledge) at the model's pragmatic level. In this phase the role of the interpreter, the decision maker, is crucial. Without given experience in the context or domain, one may not be able to make sense of any semantics. Biases create a priori expectations of what a given relationship means or what the effects of a given context might be. Here, values work as stronger mental stigmas than biases to influence the interpreter's reactions. While biases may predispose one to certain prejudices regarding semantics, values can prevent this concern from ever occurring. The essence of information processing through use of the semiotic model is to derive knowledge that is both correct and actionable.
While at the pragmatic level we generate actionable knowledge or insights, the dissipation phase calls for modification in an organization's behavior that is based on information procured during the generative phase. Dissipation can be defined as the act of transforming information from the realm of thought to the realm of action (Ramaprasad & Ambrose, 1999). We now descend through the semiotic levels on the right side of the model and focus on calculating and executing desired actions.
Starting at the top of the model, at the semantic level, we consider how to transform logical thought or knowledge into physical action. This requires knowledge to be viewed in the appropriate context, as defined by the organization, as well as an understanding of the organization's various constituents. Each of these contextual variables has grave implications related to the consequences of potential actions. These variables are directly dependent and related to the generation side of the model. If the effects of entropy have maximized on the interpretive side, the action as a result of dissemination may be totally without value.
If the environment is understood, and the effects of entropy neutralized, plausible actions can be considered. Plausible actions are a function of the syntactical connections between the constituents in question. To list available options, it is crucial for one to view all the relationships between the parts being affected so as to get a holistic view, and mitigate the effects of bounded rationality.
Once selected courses of actions are identified, their effects need to be calculated. This is the function of the empirical level, where we select the action to be implemented. Calculating probability statistics or running simulations on anticipated action while monitoring their effects empirically deduces the right course of action. Common approaches include what-if analysis, sensitivity functions, and so on. At the root, we now need to modify the behavior of agents or objects called for by the action chosen. Changing the behavior of agents based on information is one means of creating organization from information. This is crucial, as generation of insights has no value unless it is followed by action.
APPLYING THE LEVELS: STAGING FOR ACTION
The model presented in this article is reliant on understanding the variables associated with the scheme. As with the practical use of any model, the first independent variable governing the successful application of the model is organizational commitment. The second most important variable is time. In the first instance there is no need to begin any process regarding information flow if the organization sees no need for it. Secondly, if an organization professes a need and allocates the resources for the objectives generally associated with information management, everyone should be aware of it or the facility responsible will be crippled from the start as potential data sources are missing. And, as Einstein viewed time as a constantly flowing river of which we can only catch a fleeting glimpse, so too data and information have a relevant, observable shelf life. The element of time is closely associated with the element of risk, in that there is a direct correlation between the amount of risk to which an organization is willing to expose itself before the time is right for action. Ethics aside, both Enron and Arthur Andersen ignored this relation.
To illustrate these relations in our application, we have chosen to use a well-publicized case study that, as of this publication, is still under investigation: the use of information among US government agencies immediately prior to the World Trade Center catastrophe of September 11 (see Calabresi, 2002; Calabresi & Ratnesar, 2002; Elliott, 2002a, 2002b; Ratnesar & Weisskopf, 2002 for all data regarding intelligence failures related to September 11). Other examples that were available for use with our model included the shuttle Challenger disaster at NASA or the failures related to the Exxon Valdez (Mitroff, 1998). The reason for selecting this example is that it readily supports a variety of information-related “what-if” options that come in play using the semiotic model as well as addressing the all-too-common refrain heard following disasters: Who would have known?
THE MORPHOLOGICAL LEVEL:GATHERING GENERATIVE DATA
Gathering generative data begins with the decision to be in the information business, which is an organizational concern. Here, the presumption is that efficiency in gathering information and effectiveness in acting on the information gathered are important. At the formative level of the semiotic model, generative data is expected to be general and has potential for being unnecessary; it represents a start in data collection that may “seed” some information, hence it is generative.
Not all data will sprout useful information. The type of data collected is determined through the process of “flagging” any source that fits rather broad, though established, parameters. Sources of this type of data may be trade or foreign journals, newspapers, lectures, rumors, or even something on Oprah. It is more critical to begin the process of the semiotic model than to become weighed down in overanalyzing the types of data that should be collected. In our example, we will see that media reports from several sources served to provide an outline for the types of data that were likely to be available but, for lack of any coordinated scheme, were not channeled properly. If you plant no seeds because you are undecided whether you want radishes or corn, your yield will be the same.
An example of a flagging approach that refines data is “parenting” software that captures, and then inhibits, any access to requests of a browser to visit internet sites containing predetermined blocks of letters. At this stage it is unimportant whether the data collected is relevant to anything beyond the parameters that have caused the data to be captured; we are merely initiating the staging process. Sources of information may be determined at this stage and, to be effective, should be divergent; that is, they should embrace and reflect the ultimate needs of units within the organization whose purposes serve common objectives of the organizational mission.
In the months preceding September 11, the United States accepted a new presidency under conditions that came close to challenging constitutional authority. The subsequent transition of political parties in the White House was less than cordial, but included an exchange of information regarding world terrorist activity. Starting in December 2000, the intelligence community indicated that its surveillance activities had monitored unusual spikes in the amounts of communications traffic between known terrorist factions. This traffic was steadily consistent through June and the CIA, in particular, was concerned with the possibility of terrorist strikes intended to coincide with either July 4 or perhaps during the President's appearance at the G-8 economic summit scheduled for late July in Genoa, Italy.
There appeared to be little focus on the probabilities associated with strikes aimed at domestic targets. This posturing underscores a point made by John Parachini of the Monterey Institute of International Studies, who had repeatedly warned against the weakness in Washington's ability to calculate threat assessments because they rely, too often, “on what people think terrorists could do … [and not] on what they are able to do” (Dickey & Nagorski, 2001). Literal thinking of this type impedes considerations that allows the data process to succeed along the levels of the semiotic model. The following data would have been useful at the metamorphic stage in the development of a semiotic model:
- December 2000-March 2001: Intelligence sources, including the CIA, become aware of increased communications activity among Islamic extremist groups. Such activity is often an indication of impending action from among the participants.
- February 2001: An Arizona flight school reports to the FAA that an Arab student, Hani Hanjour, may have a fraudulent pilot's license and is seeking advanced certification to fly jets. The FAA allows Hanjour's credentials but informs him that he will not be certified. Hanjour was on board and may have piloted the plane that struck the Pentagon on September 11.
Again, at the morphological level, the task merely requires the gathering of data such as that listed above. Frankly, at this stage the focus is on the quantity rather than the quality of the information. As data filters upwards in the model, it will quickly be thinned.
EMPIRICS:FIRST-LEVEL ANALYSIS OF DATA
At this level, data has been broadly filtered but not critically evaluated. This stage of appraisal should validate usefulness and give weight to the significance of the data collected, as well as determine whether synthesis of the data is likely to provide information. This process ascribes “value” to data. Examples from the media indicate the likelihood that some data related to September 11 may have reached a level similar to the empiric stage of the semiotic model:
- June-July 2001: In a memo to his superiors, an Arizona FBI agent theorizes that Al Qaeda may be training pilots to use planes in terror plots; supervisors defer the memo.
- The Egyptian government tells the CIA that Muslim terrorists may intend to use planes to crash into buildings.
- A member of the Senate Intelligence Committee (SIC) tells CNN that her staff has advised her of the high “probability of a terrorist incident within the next three months.”
SYNTACTICS: THE RELATIONAL INTERPRETATION OF DATA
A counter-terrorism expert named Thomas Bradey reviewed suspected failures in US intelligence gathering by the 13 agencies involved in information analysis and observed that failures are less related to the collection of information but more to “failures to put [it] together properly” (Anderson, 2002). This notion should be expanded. In learning development, specific objectives are contained in the principal domains related to instructional design. These domains included the cognitive domain. Bloom (Bloom et al., 1956) stated his taxonomy of cognitive objectives according to levels of increased intellectual capacities related to comprehension (lowest level of understanding), application, analysis, synthesis, and, finally, evaluation (highest level of understanding). Because capacity on the part of the learner is essential as the tasks associated with the higher levels become more complex, it becomes important to establish competency in the lower levels before attempting to proceed to the next level of understanding. Similarly, in order succeed to the higher, more task-intensive levels of the semiotic model, previous levels must be mastered. It is a mistake to assume that an analyst can bypass levels within the process for quick, or accurate, answers.
The syntactic level is a crucial stage in which collected data has been purposefully synthesized in order to uncover the possible existence of meaningful relationships from divergent sources. Here, deductive processes come into play to establish a virtual reality on which preliminary decision making will be based. Half-way through the model, experience and ideas begin to transform en route to action-events. Again, if previous levels are bypassed or neglected, the effectiveness of any anticipated action will be in jeopardy. In our case, we see a number of activities among agencies that are reactionary because available intelligence was not channeled properly along the semiotic model:
- August 2001: The CIA asks INS to place a suspect from the October 1999 attack on the USS Cole, Khalid al Midhar, on a watch list. This is in response to the FBI informing the CIA of its arrest of Zacarias Moussaoui, a known Islamic extremist who had been attending flight school training at a Minneapolis center. The INS informs the CIA that al Midhar had entered the US in July and his whereabouts is unknown. Al Midhar is one of the hijackers aboard the plane that crashes into the Pentagon on September 11.
- Early September 2001: A Minnesota FBI agent writes an analytical memo based on Moussaoui's case, theorizing a scenario in which Islamic extremists fly a plane into New York's World Trade Center. The SIC seeks a meeting with Vice President Cheney to address terrorism, but is informed by the chief of staff that it will take six months' preparation before such a meeting can take place.
- September 11, 2001: Despite the erratic behavior of four in-flight jets on the US East coast, no information is provided to or by any authority that might have indicated a threat. Following the crash at the first tower, no type of threat alert is issued. When the second tower is attacked, there is confusion. In a seemingly “unrelated” incident, a third jet crashes 40 miles southeast of Pittsburgh. Extrapolation of that flight's course would have indicated that it was pointed in the direction of the Capitol. The fourth flight makes a wide pass over Washington before banking and possibly heading for the White House, but crashes into the Pentagon. The nation's air defenses are scrambled.
ENTROPY: THE MEASURE OF UNCERTAINTY WITHIN A SYSTEM
By late June 2001 there appeared to be a specific “message” building indicating that there might be cause for concern on the part of the intelligence community. The channel carrying that message experienced noise, like all channels, but it also contained elements of certainty associated with the message. Before we regard the state of uncertainty of the receiver, who should have been receptive to new information, we must regard elements of the state of positive certainty, which, in the broad sense, also occupy the channel. This certainty rests with experience.
The World Trade Center had been a target of religious fanatics in 1993. Subsequent terrorist activities against American interests, albeit overseas, gave no indication that such activities would abate. Individual bombers who strapped themselves with explosives were always a concern of the intelligence community until larger bombs were found in parked cars. Cars near secured buildings were checked until terrorists started driving trucks into their targets and then barricades were erected. In 1999 a US warship was attacked by a small, simple water craft fitted with explosives and the Navy ordered procedural changes. However, it appeared that the methods used by terrorists were expanding. It should not have been too much of a stretch to consider that someday planes might be used. The possibility had been presented in US popular fiction (Clancy, 1994).
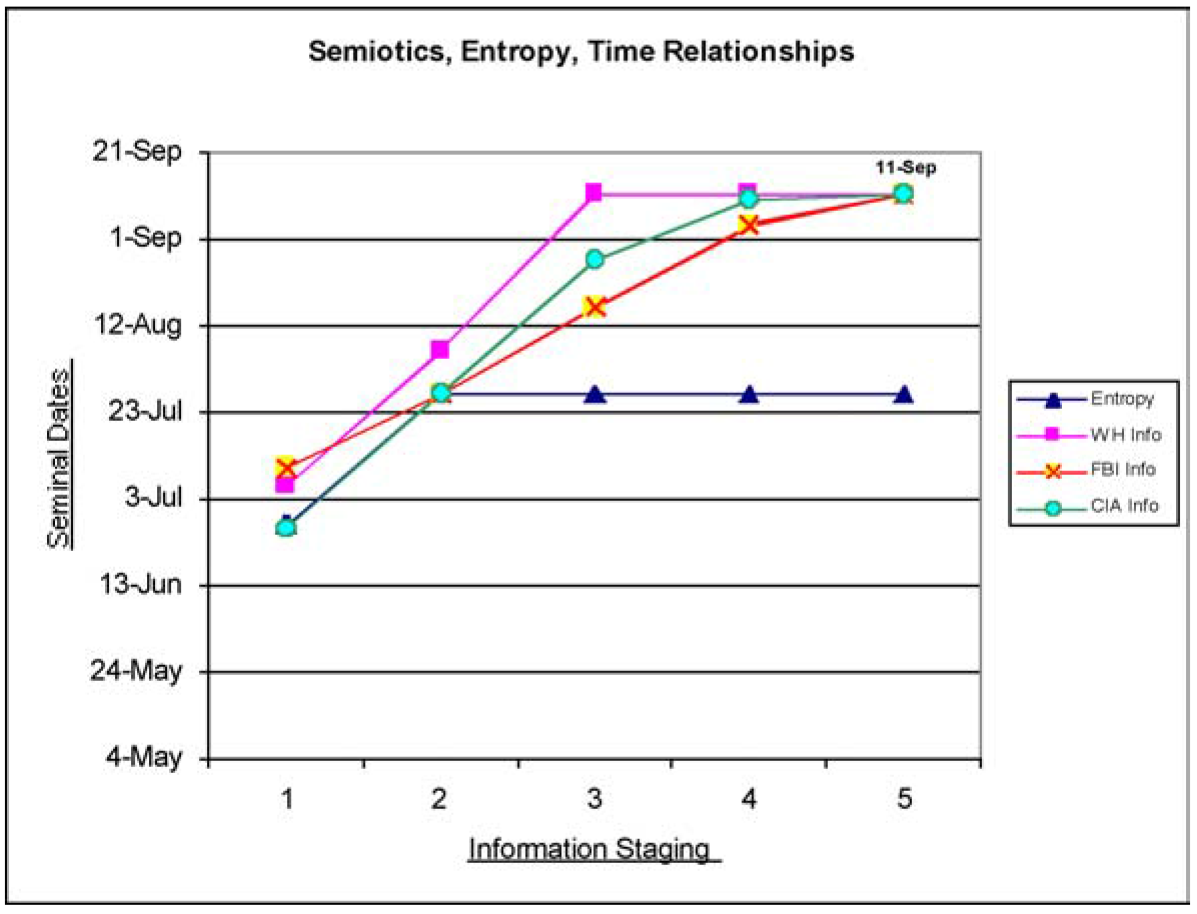
Figure 2 Staging for action
Under this case's existing information structure, any certainty that might have resulted in a positive actionable event was lost by mid-July 2001. This does not imply that the events of September 11 could have been averted, but the probability of a less reactionary response is certainly higher. In the best-case scenario, scores of lives might have been saved.
In Figure 2 the stages of the semiotic model are represented along the x-axis, starting with the morphological level (data gathering) at stage 1 and ending with the pragmatic level (beginning of action-events) at stage 5. The y-axis indicates date ranges when data, information, or independent action was taken prior to attaining the pragmatic level.
Data related to September 11 had been coming in to various intelligence centers since the beginning of 2001 and had escalated by the summer. The lack of understanding of any relational basis for this data failed to become apparent until late July, when there was a convergence affecting the major players involved in intelligence gathering and prompting the possibility of common concern. Instead of taking advantage of any joint use of some plan that might have approached the semiotic model, the players continued along independent paths. It is here where any chance for certainty (for decisions) broke down and the inevitable chance for greater entropy increased. The principal players converged again on September 11, while conditions of entropy that might have efficiently lowered in late July instead maximized.
DISSIPATION
Plausible actions are a function of the semiotic model. The process includes sequencing through the stages for a second pass starting, this time, at the top level (pragmatic) and working down to the morphological level. The purpose is to gather new data related to any action-events born as a result of the implementation of the generation-side process. The task objective includes the action of “debriefing” members associated with each level as to the effect (success or failure) of their contribution to the ultimate decision(s) for action.
This facet of the process does more than merely inform: It establishes a bond among members (organizational units) regarding their role in information and knowledge creation. While important, this aspect is often overlooked in practice, although it is supported in some of the more recent literature (Nonaka, 1994; Desouza et al., 2003).
If one were to imagine two representations of Figure 1 placed side by side, one would understand that the conclusion of the semiotic cycle on the left side, generation through dissipation, begins the cycle again as other data associated with actions through knowledge dissipation on the right side of the semiotic model. Ultimately, the scope of the effects related to this model is intended to modify the behavior of personnel involved at the various levels of the generation side of the model. The change will be based on information use (or nonuse). This is crucial, as the generation of information that approaches insight (knowledge) has no value unless it is acted on.
EMERGENCE
George Henry Lewes coined the term emergence (Lewes, 1875). Emergence can be defined as the denomination of something new that could not be predicted from the elements constituting the preceding condition. We can distinguish between “resultants” and “emergents,” that is between properties that can be predicted and those that cannot be predicted. Emergence can also be thought of as the deriving bottom-up order. To quote Conwy Lloyd Morgan:
Under what I call emergent evolution stress is laid on this incoming of the new. Salient examples are afforded in the advent of life, in the advent of mind, and in the advent of reflective thought. But in the physical world emergence is no less exemplified in the advent of each new kind of atom, and of each new kind of molecule. It is beyond the wit of man to number the instances of emergence. But if nothing new emerges—if there be only regrouping of pre-existing events and nothing more—then there is no emergent evolution. (Lloyd Morgan, 1923: 1-2)
The notion of emergence is salient for our semiotic model. Order is derived from the bottom up and is enforced top down. Knowledge, that is “pragmatics,” is derived from observing the behavior of agents at the morphological level, from understanding relations among the signs emulated by an agent or object (empirical) and among agents or objects (syntactical), and finally from making semantic connections. For instance, signs are observed from the appropriate agents at the morphological levels and can be comprehended; “myth knowledge” rather than “actionable knowledge” will emerge. This will then lead to poor dissipation activities.
Using the semiotic model proposed can contribute to understanding the dynamics of emergent knowledge, which we define as pragmatics that emerge through observing signals emulated from agents or objects at the various semiotic levels. While we do not disagree with the view that emergent knowledge cannot be predicted from elements constituting the preceding condition, our semiotic model enables one to be better prepared to act on emergent knowledge. Each level of the semiotic model helps one deduce emergent structures of signs emulated by agents or objects (Bass, 1994). While these structures may not be purely chaotic or strictly deterministic in the beginning, over time an organization will be better prepared to predict structures among signs and be able to act efficiently and effectively on the emergent structures, that is, “knowledge.”
CONCLUSION
The “Monday morning quarterback” approach involving any model applied to past conditions is easy to dismiss. Yet some of the cases for building better management approaches have come from examining past failures in order to improve strategies (Janis, 1971). The intent of this article is to demonstrate that there is an effective tool, the semiotic model, that if used properly will inhibit the barriers to efficiency in the collection of what becomes useful organizational information, which, in turn, should demonstrably play on the effectiveness of decisions leading to action-events. This article serves as the cornerstone for establishing a larger model of knowledge management maturity, a system for operations managers (Ramaprasad & Desouza, 2002).
It should be noted that while other useful semiotic models exist, each, like ours, is for a purpose determined by specific boundaries. For example, work done by the French structural linguist Greimas (1983, 1987) specifically addresses the essence of transformational meaning. We agree with the terms of his boundaries, in that relations must exist between the entities of the model and meaning is affected during the trajectory of discourse between the entities. Greimas's use of the semiotic square to analyze paired, relational concepts results in a wide variety of effective interpretations, which may serve to fill a semantic gap in a static environment. Static targets are easier to hit than dynamic targets. Consequently, the semiotic square can be easily applied in defense of subjective opinion, especially if the objective is to undermine applications based on binary logic decisions. Further, the fallacy associated with such considerations is easily dismissed using the tools available to any first-year calculus student. We believe that we are in agreement with Greimas's intentions of providing a useful model that is not merely intended to advance, but rather to demonstrate, a useful purpose. Greimas seeks meaning deductively through associations between paired concepts represented in an example using a semiotic square. We chose to reason inductively in an effort to represent a totality.
Another interesting perspective is provided by Robert Hodge and Gunther Kress in their work on social semiotics (Hodge & Kress, 1988). Their agenda is driven and motivated by the following: culture, society, and politics as intrinsic to semiotics; other semiotic systems alongside verbal language; parole, the act of speaking, and concrete signifying practices in other codes; diachrony, time, history, process, and change; the processes of signification, the transactions between signifying systems and structures of reference; structures of the signified; and the material nature of signs.
Surrounding the potential for success of any model is the issue involving complexity. Here, complexity should be addressed in a couple of ways. First, in the general sense, it has been said, “To the ignorant, the world looks simple” (Dörner, 1996). In this instance, complexity again refers to uncertainty, which we have addressed. When one believes all things to be certain there is a tendency to dismiss new knowledge regardless of its form or origin. Prior to the events of September 11, a common American expression of reminiscence saw life in the past as easier, possibly more pleasant, because “it was a simpler time.” The comparison is, of course, selective: The “time” was less complex in terms of the general consumption of information. In our argument, complexity is closely related to uncertainty. To continue our analogy, any given point in time was not simpler, but the allusion of certainty may have been much greater. Following the Second World War lines were simply drawn for a Cold War between the two superpowers with little regard for the rest of the world; a classic good-guy, bad-guy scenario. But the situation became less simple (more complex) as the timeline associated with events indicated a complexity in which the good guys planted the seeds, in 1953, for the repatriation of an Islamic fundamentalist Ayatollah to Iran. And why was it that the bad guys were the ones supporting a popular revolutionary who had deposed a self-serving dictator that had kept the population in poverty and ignorance on an island 90 miles south of the United States? By extension and causation, a case for the destruction of the World Trade Center might be tied to the launching of Sputnik in 1957, when “times were simpler.”
The second aspect of complexity involves the semiotic model presented in this article. The first issue is whether the model is actually workable; that is, is it likely that data can ultimately be transformed into meaningful information as a basis for knowledge on which actionable events will occur? In a general sense, the question is rhetorical because the process takes place daily for individuals, organizations, and governments. However, individuals, organizations, and governments often work under conditions that support tolerance of counter-productivity. Sometimes these conditions are a result of what Herbert Simon describes as bounded rationality, but more often they are the result of not using what is available. Long after this article is published, “new” information will come forward in support of data that was available, and not used, that would have allowed the United States to be far better prepared against terrorist attacks generally and, though unfortunate, the World Trade Center attack specifically.
Amid the confusion and destruction in New York on September 11, there was a haunting, ironic note that underscores the importance of the use of the model we have presented: Few, if any, New York firefighters who responded were “surprised” that the World Trade Center had been the target for destruction. It appears that their understanding of the possibility of the event was more complex than many whose job it is to prevent such disasters. The use of the semiotic model could have converted the tacit feeling shared by the NYFD into the realm of useful data available to other governmental guardians.
Once the semiotic model is in place, future considerations will involve conditions of the model's flexibility under conditions of changes to previously bounded ranges, adaptability without disruptive changes when organizational structures are modified, and exaptability during which new features may be developed for functions other than those for which the model was developed. Each of these facets will be bound to organizational creativity and, ultimately, to the human knowledge workers who will provide the key commodity among future organizational resources (Drucker, 1993). Organizational information processing is a key determinant of survival in today's economy.
NOTES
- A similar notion exists in Kant's (1929) synthetical a priori arguments in mathematics and science regarding knowledge. He is essentially saying, see it for what it is rather than what someone has interpreted it to be for you.
- Ramaprasad and Ambrose (1999) apply a four-staged (morphological, syntactical, semantic, pragmatic) one-dimensional model to explain knowledge management in organizations. Desouza and Ramaprasad's (2002) model can be viewed as an extension of their framework in two crucial aspects. First, they add another layer, empirics, to explain the generation and dissipation of information. Secondly, they look at the significance of efficiency and effectiveness at each level.
References
Andersen, P B. (1991) A Theory of Computer Semiotics: Semiotic Approaches to Construction and Assessment of Computer Systems, Cambridge, UK: Cambridge University Press.
Anderson, K. (2002) “US intelligence efforts fractured,” BBC News Online, 18 May.
Bass, N. A. (1994) “Emergence, hierarchies, and hyperstructures,” in C. G. Langton (ed.), Artificial Life III, SantaFe Studies in the Science of Complexity, Proceedings Volume XVII, Redwood City, CA: Addison-Wesley: 515-37.
Bloom, B. S., Drathwohl, D. R., & Masia, B. B. (1956) Taxonomy of Educational Objectives: The Classification of Goals, New York: David McKay.
Calabresi, M. (2002) “What the spies know,” Time, February 18, 159(7): 32.
Calabresi, M. & Ratnesar, R. (2002) “Can we stop the next attack?,” Time, March 11, 159(10): 24-37.
Campbell, J. (1982) Grammatical Man, New York: Simon & Schuster.
Clancy, T. (1994) Debt of Honor, New York: Berkley Press.
Clarke, R. J., Liu, K., Anderson, P B., & Stamper, R. K. (eds) (2001) Information, Organization and Technology: Studies in Organizational Semiotics, Boston, MA: Kluwer Academic Publishers.
Dalmadge, C. (2000) “A method for measuring the risk of e-business discontinuity,” unpublished doctoral dissertation, Carbondale, IL: Southern Illinois University.
Desouza, K. C. (2001) “Intelligent agents for competitive intelligence: Survey of applications,” Competitive Intelligence Review, 12(4): 57-63.
Desouza, K. C. (2002) Managing Knowledge with Artificial Intelligence, Westport, CT: Quorum Books.
Desouza, K. C. (2003) “Barriers to effect knowledge management: Why the technology imperative seldom works,” Business Horizons, forthcoming.
Desouza, K. C. & Ramaprasad, A. (2002) “Semiotics of information in organizations: A three dimensional framework,” working paper, Chicago, IL: Department of Information and Decision Sciences, University of Illinois at Chicago.
Desouza, K. C., Jayaraman, A., & Evaristo, J. R. (2003) “Knowledge management in non- collocated environments: A look at centralized vs. decentralized design approaches,” in Proceedings of the Thirty-Sixth Hawaii International Conference on System Sciences (HICSS-36), Los Alamos, CA: IEEE Press.
Dickey, C. & Nagorski, A. (2001) “Who's the mastermind?,” Newsweek Web Exclusive, (http://www.msnbc.com/news/627496.asp).
Dickson, P (1978) The Official Rules, New York: Delacorte Press.
Dörner, D. (1996) The Logic of Failure, Cambridge, MA: Perseus Books.
Drucker, P (1993) The Post Capitalist Society, Oxford, UK: Butterworth Heinemann.
Elliott, M. (2002a) “How the U.S. missed the clues,” Time, May 2, 7159(21): 24-32.
Elliott, M. (2002b) “They had a plan,” Time, August 12, 160(7): 28-42.
Greimas, A. (1983) Structural Semantics, Lincoln, NB: University of Nebraska Press.
Greimas, A. (1987) On Meaning: Selected Writings in Semiotic Theory, trans. P J. Perron & E H Collins, London: Frances Pinter
Hardin, G. (1968) “The tragedy of the commons,” Science, 162: 1243-8.
Hodge, R. & Kress, G. (1988) Social Semiotics, Ithaca, NY: Cornell University Press.
Janis, I. L. (1971) “Groupthink: The desperate drive for consensus at any cost,” Psychology Today; reprinted in J. M. Shafritz & J. S. Ott (2001) Classics of Organization Theory. Fort Worth, TX: Harcourt Brace: 185-92.
Kant, I. (1929) Critique of Pure Reason, trans. N. K. Smith, New York: Macmillan.
Lewes, G. H. (1875) Problems of Life and Mind, Vol. 2, London: Kegan Paul, Trench, Turbner.
Liu, K. (2000) Semiotics in Information Systems Engineering, Cambridge, UK: Cambridge University Press.
Lloyd Morgan, C. (1923) Emergent Evolution, London: Williams and Norgate.
Lyons, J. (1977) Semantics, Vol. I, Cambridge, UK: Cambridge University Press.
Maes, P (1995) “Agents that reduce work and information overload,” Communications of the ACM, 37(7): 30-40.
Mitroff, I. (1998) “Crisis management: Cutting through the confusion,” Sloan Management Review, 29(2): 15-20.
Newman, J. (2001) “Some observations on the semantics of information,” Information Systems Frontiers, 3(2): 155-67.
Nonaka, I. (1994) “Dynamic theory of organizational knowledge creation,” Organization Science, 5: 14-37.
Pierce, J. (1980) An Introduction to Information Theory: Symbols, Signals and Noise, New York: Dover Publications.
Ramaprasad, A. & Ambrose, P J. (1999) “The semiotics of knowledge management,” Workshop on Information Technology & Systems, Charlotte, NC.
Ramaprasad, A. & Desouza, K. C. (2002) “Knowledge management maturity model: Operability, flexibility, adaptability, exaptability, agility,” working paper, Chicago, IL: Department of Information and Decision Sciences, University of Illinois at Chicago.
Ramaprasad, A. & Rai, A. (1996) “Envisioning management of information,” Omega, 24(2): 179-93.
Ratnesar, R. & Weisskopf, M. (2002) “How the FBI blew the case,” Time, June 3, 159(22): 24-32.
Shannon, C. E. (1963) The Mathematical Theory of Communication, Urbana., IL: University of Illinois Press.
Shrivastava, P (1987) Bhopal: Anatomy of a Crisis, Cambridge, MA: Ballinger. Simon, H. A. (1960) The New Science of Management Decision, Englewood Cliffs, NJ: Prentice Hall.
Simon, H. A. (1996) The Sciences of the Artificial, Cambridge, MA: MIT Press. Watzlawick, P, Bevin, J. H., & Jackson, D. D. (1967) Pragmatics of Human Communication, New York: Norton.
Wittgenstein, L. (1953) Philosophical Investigations, New York: Macmillan.