The influence of heterogeneity on knowledge-based agglomeration economies:
Emergent patterns of geographical clusters
Ilaria Giannoccaro and Vito Albino
Politecnico di Bari, ITA
ABSTRACT
We examine the concept of knowledge externalities, namely the benefits that co-located firms receive in terms of knowledge, focusing on the role of interactive learning processes and adopting the single firm perspective, whereas in literature their role has mainly been analyzed adopting the system perspective and focusing on knowledge spillovers. The geographical clustering process is studied as an emerging property of a system made up of independent firms making location choices. The aim of the paper is to analyze how the firm heterogeneity affect the geographical clustering process. In fact, so far literature and empirical evidence do not provide a conclusive answer to this regard. To pursue our aim, an agent-based model of geographical clustering is developed, based on knowledge externalities produced thanks to learning by imitation and learning by interaction and a simulation analysis is then carried out. The main result is that the heterogeneity reduces the willingness of firms to geographically cluster and enhance the development of knowledge.
Introduction
Agglomeration economies are positive externalities (benefits) resulting from the spatial clustering of economic activities and motivating firms to form geographical clusters (GCs). In traditional studies on the topic, agglomeration economies are argued to be driven by production externalities, namely how co-locating affects the cost of productions and firms’ production technologies. In fact, the benefits for co-located firms include production cost reductions and/or an increased production efficiency (Marshall, 1920; Krugman, 1991; Porter, 1998).
However, literature have recently overcome the logic of static economies of agglomeration that focus on efficiency gains and devoted increasing attention to dynamic agglomeration economies, which highlights the central role of learning and knowledge creation (Ernst, 2002).
The dynamic agglomeration economies are based on knowledge externalities. This however is not a new concept: it can be already found in Marshall (Marshall, 1920), who recognized knowledge spillovers as a key factor motivating firms to geographically cluster. Geographical proximity favors information flows among people and facilitates the exchange of tacit knowledge among firms.
Several empirical studies have confirmed that knowledge spillovers are geographically bounded (Jaffe et al., 1993; Audretsch & Feldman, 1996) and have highlighted their positive influence on innovative performance of firms (Baptista, 2000). Firms near knowledge sources in fact introduce innovations faster than firms located elsewhere.
Thus, knowledge externalities affect agglomeration economies and motivate firms to form GCs so as to gain knowledge benefits. Firms can gain benefits from co-location not only in terms of lower costs or improved efficiency in production but also in terms of increased knowledge stocks.
Even though knowledge externalities have recently received dramatic attention in the economic literature and despite the number of different schools of thought that have analyzed the topic, adopting diverse perspectives, the concept remains ambiguous and is considered as a “black box” (Breschi & Lissoni, 2001). Knowledge spillover1 are often considered exogenous to the system and are analyzed adopting a system level perspective (Maskell, 2001b; Giuliani & Bell, 2005). The whole GC is considered as the unit of analysis, phenomena and dynamics are observed at the macro level, and little attention has been devoted to identify how and how much each firm may exploit and contribute to knowledge externalities.
Some scholars have in fact questioned that all firms equally benefit from agglomeration economies. The benefits that they gain vary by firm to firm. The gain depends not only on the absorptive capacity of the firm (i.e., the ability to understand and use the new knowledge) but also on how much the firm contributes to knowledge spillovers. Firms in fact have to compare the new knowledge they can absorb with the knowledge that from them spill over to the other firms (Alcacer, 2006; Shaver & Flyer, 2000; Alcacer & Chung, 2007). If the net knowledge spillovers (i.e., the difference between the inward knowledge and the outward knowledge spillovers) are negative, the firms will prefer to not agglomerate (Alcacer & Chung, 2007).
Therefore, it is expected that the heterogeneity of the firms influences the agglomeration process. In fact there is evidence that co-location patterns vary by firm activity and capability. Alcacer (2006) finds that production and sales units are more geographically dispersed and R&D units are more concentrated compared with a random distribution of activities. Shaver and Flyer (2000) show that low technology firms tend to form clusters while the best in class ones tend to be located at a distance.
It is thus expected that GCs will be formed by low-level firms while high-level firms will avoid this location in order to protect their knowledge. Nevertheless, an opposite result has been observed by Giuliani (2007), who finds that GCs in the wine sector are characterized by very few firms with a strong knowledge base and many firms with weak knowledge bases. Thus, it seems that also the best in class firms benefit from co-location, even though they tend to protect their knowledge by reducing the connections with the low-level firms.
Given that the empirical evidence and the literature do not provide a conclusive answer, we are spurred to more in deep investigate on how the heterogeneity of the firms influences the geographical clustering process.
To address this research question, we adopt an approach that overcomes the foregoing limitations of the studies on knowledge spillovers: i) we adopt the single firm perspective by studying the emergence of the GC as the result of the firm location decisions rather than to use a system level one and ii) we consider the learning processes as sources of knowledge spillovers rather than to give the existence of the knowledge spillovers exogenously. Since the source of knowledge spillovers usually investigated in the literature refer to the R&D investments, we believe that our study focusing on the learning processes is an innovative contribution to the literature.
In particular, our argument is that knowledge spillovers are produced thanks to two specific interactive learning processes, i.e. learning by imitation and learning by interaction, and that firms choose their location in order to benefit from enhanced learning opportunities. Moreover, the extent to which the learning processes develop knowledge stock and how firms are able to exploit this knowledge is influenced not only by the geographical proximity but also by the cognitive proximity. Therefore, the net knowledge spillovers of a firm in a given location depends on the geographical and the cognitive proximity and by the firm absorptive capacity. The optimal location of a firm is thus the result of a complex phenomenon involving multiple actors and depending on diverse variables that affect it in a non linear manner.
For this main reason, the research methodology we chose is the agent-based simulation (ABS). It is a computational technique that originated in complexity science to examine complex adaptive systems (CASs) and has recently been applied to economic, organization and strategic studies (Axelrod, 1997; Rivkin, 2000; Siggelkow & Rivkin, 2005; Tesfatsion & Judd, 2006; Davis et al., 2007). The main goal of ABS is to enrich our understanding of the fundamental processes regulating and determining the dynamics of CASs, by using a bottom-up approach, according to which the system dynamics emerge as the spontaneous result of the interactions among independent agents. This is also consistent with the complex adaptive system nature of GCs (Carbonara et al., 2006).
This methodology is particularly valuable for our study because it permits to provide an examination of the geographical clustering process coherently with our theoretical approach: (i) adopting the firm perspective, and (ii) taking into account how the decisions of multiple actors forge the behavior of the whole system. In this way the GC will spontaneously emerge from the self-organized and spontaneous interactions among firms (Albino et al., 2003; Carbonara et al., 2006).
Furthermore, the simulation is used as a laboratory to analyze the effects of firm heterogeneity on the geographical clustering processes. To do this, we create the agent behavior on the basis of stylized facts coming from the literature and we observe the spatial clustering of the agents as an emergent behavior during the simulation. Agents are located on a grid (the geographical space), interact each other, and develop their knowledge stocks thanks to learning. The goal of each agent is to maximize the net knowledge spillovers. To pursue this goal, the agent can move around the grid looking for new positions that could increase the net knowledge spillovers.
A simulation analysis is finally carried out to analyze through computational experimentation the influence on the geographical clustering process of the heterogeneity of the agent knowledge stock.
The paper is organized as follows. Firstly, the theoretical background of the research is presented. Then, the agent-based simulation is briefly presented and the main models of the GCs developed in the literature are reviewed. The model of the geographical clustering process based on knowledge externalities is then discussed. The simulation analysis is finally carried out and main findings discussed.
Theoretical background
Geographical clusters, agglomeration economies, and knowledge spillovers
Among the different types of spatial concentration of related industries and firms, geographical clusters (GCs) are geographical concentrations of interconnected companies and institutions operating in a particular field. They include: suppliers of specialized inputs such as components, machinery, and services, providers of specialized infrastructures, manufacturers of complementary products, companies in related industries, and customers. Many clusters may also include governmental and other institutions such as universities and research centers (Porter, 1998). In this work we consider GCs as geographical concentrations of firms, featuring the co-localization of a large number of firms involved in various phases of production of a homogeneous product family. These firms are generally highly specialized in a few phases of the production process, and integrated through a complex network of inter-organizational relationships (Pouder & St. John, 1996).
Agglomeration economies are positive externalities (benefits) resulting from the spatial clustering of economic activities and motivating firms to form GCs. The benefits for co-located firms include production costs reductions and/or an increased production efficiency. For Marshall (1920), the industry localization may generate production externalities deriving from the existence of an industry demand that creates a pool of specialized labor and a pool of specialized input providers. For Krugman (1991), the benefits of agglomeration in essence depend on three factors: i) substantially increasing returns to scale, both at the level of single firms (internal economies) and the industry (external economies); ii) lower transportation costs; and iii) a large local demand.
More recently, spurred by the new strategic management theories recognizing that knowledge is the fundamental factor that creates an economic value and competitive advantage for firms (Leonard-Barton, 1995; Spender, 1996; Grant, 1997), the logic of agglomeration economies has been rethought and a renewed attention has been devoted to knowledge externalities, namely the benefits that co-located firms receive in terms of knowledge.
This concept was originated by Marshall (1920), who identified in knowledge spillovers a further factor motivating firms to form GCs, and has been investigated by distinct schools of thought, adopting various perspectives: economic geographers have studied the relationship between localized knowledge spillovers and innovation (Marshall, 1920; Audretsch & Feldman, 1996); regional economists have developed the concept of collective learning (Baptista, 2000; Capello & Faggian, 2005); the French school of proximity has placed emphasis on the influence of distinctive dimensions of proximity on learning (Boschma, 2005); management scholars have investigated the nature of knowledge circulating in GCs, the knowledge transfer and creation processes embedded in GCs and the learning processes (Pinch et al., 2003; Tallman et al., 2004; Albino et al., 2006).
The existence of knowledge externalities explain why firms tend to forms GCs: they receive benefits in terms of increased knowledge that is the most strategically important of a firm's resources and plays a critical role in gaining and keeping the competitive advantage.
However, as firms benefit from knowledge externalities they also contributes to them, because increase the knowledge stock of the nearby firms (Shaver & Flyer, 2000; Alcacer & Chung, 2007). If the net result of knowledge spillovers is negative, the co-location is not beneficial for the firm because it will lose competitive advantage with respect to the other firms. Thus, the firm will prefer to relocate at a distance from the others. Consider a start-up firm in the high-tech industry; it will prefer to locate in Silicon Valley where it can benefit from watching, discussing, comparing solutions with related firms located in the GC. It could exploit the other firms’ s mistakes and successes, identify the top-performers and imitate their “good” capabilities. On the contrary, the top-performers, having superior capabilities, will learn very much less from the less capable firm as compared with what the latter can learn from the more capable firm. Thus, in terms of competitive advantage, the start-up firm will gain a positive net benefit whereas the sum is negative for the top-performer. As a result, the top-performer will not have the incentive to co-locate but, on the contrary, to locate at a distance from the less capable firm. Thus, the following stylized facts are defined:
- Geographical clusters emerge from the firm location choice.
- The firms choose the location that maximize the net knowledge spillovers, i.e., the difference between the inward spillovers and the outward spillovers.
Sources of knowledge spillovers in geographical clusters: An approach based on learning processes
Among different sources of knowledge spillovers we put our attention on the learning processes. In particular, we assume that agglomeration economies are benefits that firms receives in terms of enhanced learning processes, which in turn enhance the knowledge stock and technological capabilities of firms, thereby generating continuous change and innovation and not just simple average cost reductions (Malerba, 1992).
To identify the learning processes important as sources of agglomeration economies, we look at the learning processes activated in the GCs that are the most significant in terms of creation of an environment conducive to innovation. We identified that the most important inter-firm learning processes activated in GCs are: learning by localizing, learning by imitation, and learning by interaction (Albino et al., 2006; Pouder & St. John, 1996; Keeble et al., 1999; Baptista, 2000; Giannoccaro, 2015).
Learning by localizing (or collective learning) allows GC firms to develop their knowledge stocks thanks to their sense of belonging to the area, their capability of interacting and their sharing of common values. The internal cohesion promotes the introduction of new products or production techniques and reduces the uncertainty associated with innovations (Camagni, 1995; Gertler, 1995).
Learning by imitation occurs as a result of imitation and emulation processes among firms. The focused environment of the GC, the sharing of common conditions and the transparent circulation of information makes it easy to observe successful and failed strategies adopted by each individual firm. In this way firms can learn from experiences made by other firms, emulating the success of others and adding something new of their own (Belussi & Arcangeli, 1998). Learning by imitation can also take place without any explicit interaction between local agents. In fact, even in absence of close contacts and interactions, firms can monitor each other constantly, closely, and almost without effort or cost (Maskell, 2001b).
Learning by interaction derives from the interactions among firms belonging to networks of formal and established business relationships. It takes place when firms interact with their suppliers and customers. In the first case information and knowledge are embedded in the components and semi-finished products supplied, and in subcontracting technical specifications. Interactions with customers can stimulate exploitation of the firm knowledge and creativity to develop product innovations that are able to satisfy the customer needs (Piore & Sabel, 1984).
Learning and proximity: Influences on knowledge development and access
We mainly refer to the regional economy literature to identify the extent to which the learning processes develop knowledge stock and firms are able to absorb the developed knowledge. This body of literature represents the theoretical framework upon which we build our agent-based model. In particular, it is used to define further stylized facts of our simulation model.
Regional economy researchers have in recent years investigated the relationship between proximity, innovation, and learning. In particular, The French School of Proximity has highlighted that different and intertwined dimensions of proximity affect the interacting learning processes. Five dimensions can be recognized: geographical, cognitive, organizational, social, and institutional (Boschma, 2005), but we focus herein on geographical and cognitive proximity.
Geographical proximity is defined as the spatial or physical distance between two firms. In the literature it has recently been claimed that firms that are spatially concentrated benefit from knowledge externalities (Maskell, 2001a). Short distances, in fact, enable information contacts to be created and facilitate the exchange of tacit knowledge. The larger the distance between firms, the less the intensity of these positive externalities (Boschma, 2005). This may even be true for the exchange of codified knowledge, because its interpretation and assimilation may still require tacit knowledge and, thus, spatial closeness (Howells, 2002). Thus, the following stylized fact is defined
- As geographical proximity increases, the knowledge developed by means of learning by imitation and learning by interacting increases.
However, some scholars have noticed that for interacting learning to take place the cognitive proximity is important. The term cognitive proximity refers to the similarity of the knowledge stocks of two firms.
Firms sharing the same knowledge stock and expertise may learn from each other. However, too much cognitive proximity may also have a negative impact on learning and innovation. In fact, some cognitive distance should be maintained to enhance interactive learning because knowledge building often requires dissimilar, complementary bodies of knowledge (Cohendet & Llerena, 1997). However, at a certain point cognitive distance becomes so large as to preclude sufficient mutual understanding needed to utilize those opportunities. Thus, some scholars have proposed an inverted U-shaped relation between learning by interaction and cognitive proximity (Boschma, 2005; Noteboom et al., 2007). These arguments are used to identify the following stylized fact:
- A inverted U-shaped relation characterizes the relation between cognitive proximity and the knowledge developed by interaction.
The only requirement for learning by imitation to take place is that several firms are placed in circumstances where they can monitor and compare each other's undertakings constantly (Maskell, 2001a). Firms learn from experiences made by firms with superior knowledge and try to emulate their behaviors. Imitation can potentially occur even if firm knowledge stocks are different. What the firm will definitely learn will depend on the firm's absorptive capacity (Cohen & Levinthal, 1990). Thus, the following stylized fact is defined
- Knowledge developed by imitation increases as the cognitive distance rises.
The acquisition of the knowledge developed by imitation and interaction depends on the firm's absorptive capacity, namely the firm's ability to understand and exploit in its own process the knowledge developed. The firm's absorptive capacity is mainly influenced by the cognitive proximity and the firm knowledge stock.
In their widely recognized theory on the absorptive capacity, Cohen and Levinthal (1990) argue that the simple access to new knowledge is not a sufficient condition for acquiring it. The effective transfer of new knowledge requires the firm to be able to identify, interpret, and exploit it. The authors also recognize that the extent to which a firm is able to absorb new knowledge is a function of the prior level of knowledge the firm possesses. This prior knowledge confers a theoretical framework (cognitive map) in which to interpret the new knowledge, that otherwise cannot be understood. Therefore, the cognitive distance between the knowledge stock of the firm and the new knowledge matters. For learning process to be effective interacting firms need to be close enough in terms of knowledge stocks. In fact, cognitive proximity permits them to communicate and understand each other (Boschma, 2005). The following stylized fact is derived referring to the ability of firms to absorb the developed knowledge:
- Absorptive capacity declines with the cognitive distance.
However, the absorptive capacity is also influenced by the knowledge stock of the firm. In fact, firm with minor knowledge stock (e.g. a novice in a given area) will absorb less than a more knowledgeable and experienced firm will, because the novice does not have so great an already assimilated mental map with which to interpret the new incoming information. This argument is consistent with Noteboom et al. (2007) who observe that firms with larger amounts of knowledge will generally show a better performance in dealing with cognitive distance, when compared to firms with smaller amounts of knowledge. Similarly, Giuliani and Bell (2005) measures the absorptive capacity by analyzing the level of knowledge stock a firm posses in terms of skilled workers and technical qualified personnel, degree of experience, and effort in knowledge creation activities. Thus, we define the following stylized fact:
- Higher the knowledge stock of the firm, higher its absorptive capacity.
The agent-based model of the geographical clustering process
To investigate the process of geographical clustering of firms based on knowledge externalities, we have developed an agent-based model. The model aims to study the process of geographical clustering of firms as an emergent behavior of the system. This means that GCs will emerge as the spontaneous result of the firms’ decisions and of interactions among firms. The computational implementation of the model is made using Free Pascal 1.0.10 software (Van Canneyt & Klampfe, 2005). More information on the software is available at the website link.
Main assumptions
Our model is built upon the knowledge-based theory of the firm, which considers firms as knowledge users and producers (Grant, 1997). Firms knowledge is conceptualized as knowledge stocks, in the sense of accumulated knowledge assets that are applied to produce goods and service (Decarolis & Deeds, 1999). The knowledge stock of the firm is usually identified in terms of human resources (skills, training, experience and also in terms of in-house knowledge-creation effort (usually R&D) (Cohen & Levinthal, 1990). Here, the knowledge stock of the firm is the result of a process of cumulative learning. In this step of the research, only the knowledge stocks are modeled, thus herein knowledge is the only goods produced and transferred. We do not consider different kinds of knowledge and do not distinguish between tacit and codified knowledge.
Firms are involved in location choices. In particular, we assume that location is a strategic decision for firms, i.e., firms consider the location as a source of competitive advantage (Alcacer, 2006; Alcacer & Chung, 2007; Audretsch et al., 2005). The location decision depends on the incentives caused by agglomeration externalities. Geographical relocation is costless and instantaneous.
Agglomeration economies are only based on knowledge externalities. They consist in the development of knowledge stocks to enhance learning processes. In this work two learning processes are taken into account, i.e., learning by imitation and learning by interaction. In some industries, however, collective learning may be more representative of innovation diffusions than the considered learning processes. Thus, our model better fit the features of the traditional Marshallian Industrial Districts, where the innovation carried out by firms is the result of the learning processes based on the information and knowledge flows circulating inside the district in the form of learning by imitation and by interaction, whereas different and improved learning mechanisms are less commonly used (Albino et al., 2006). We also do not consider knowledge sources external to the GC.
Learning processes are only affected by two dimensions of proximity, namely geographical and cognitive proximity. Their influence is measured in terms of increases of the knowledge stock.
Agents and environment
The agent of the model corresponds to the single firm. It is modeled as an object located in a rectangular grid (the geographical space). The number of agents (N) in the grid is defined as the population.
Each agent i is characterized by two dynamic attributes:
- the value of accumulated knowledge stock at a given instant in time Ki,t.,
- the spatial position occupied at a given instant in time on the grid Pi,t (x,y).
Given that we do not consider different kinds of knowledge stock, agents differ only as regards the amount of knowledge stock they possess.
The goal of each agent is to maximize its fitness, that is influenced by the agent's position on the grid. Therefore, during the simulation agents move around looking for new positions with higher fitness. The fitness measures the net benefits in terms of enhanced knowledge stocks that the agent receives in a given position. According to the stylized fact 2, the net benefits are the difference between the inward spillovers and the outwards spillovers. Thus, they are computed as the difference between the knowledge stocks that the agent i learns from the other agents j:
The fitness function so defined is a measure of the competitive advantage of the firm and is calculated as follows:
The agent possesses a mental model that represents its view of the external world, in the sense of what the agent knows about the other agents. Each agent knows the knowledge stock accumulated by the other agents and their position in the grid. In this first work we assume that agents know these values correctly, and we do not take errors into account.
Based on the agent attribute, we also define attributes characterizing the population. These are: the level of knowledge and its heterogeneity. The level of knowledge is computed as the mean of the agent knowledge stocks. Heterogeneity measures how different the agent knowledge stocks are. The more they differ, the more heterogeneous the population is. This attribute is calculated as the standard deviation of the agent knowledge stocks. Initial differences in heterogeneity can be due to different propensity of firms to invest in R&D or to their initial superior stock of resources. Final differences in heterogeneity are due to the developments of knowledge stock due to learning by interaction and imitation.
Actions
To build the actions of the agents we referred to the stylized facts identified in Section 2.3 and also we made further assumptions. These assumptions are supported by literature and empirical evidence (as well as on reasonable thinking).
Learning. Agents are continuously engaged in interactive learning activities, i.e., learning by imitation and learning by interaction with all the other agents of the population. The interactive learning activity is a one-to-one relation, in the sense that each agent activates N-1 learning relations at each step. Each learning relation between the agent i and the agent j determines a development of the knowledge stock of the agent i due to imitation (ΔKij,imitation) and interaction (ΔKij,interaction).
The effectiveness of the learning processes is influenced by geographical and cognitive proximity between the two interacting agents.
As to geographical proximity, it is assumed to enhance both learning processes (see stylized fact 3). Hence, ΔKij,imitation and ΔKij,interaction decrease with the increasing geographical distance between agents. Moreover, learning by interaction is assumed to develop higher knowledge stocks than learning by imitation, given the geographical distance. Since learning by interaction requires both parts to be intentionally involved in the relations and to cooperate to develop new knowledge and, on the contrary, learning by imitation occurs without any explicit interaction and coordination between firms (Maskell, 2001b), it is reasonable to assume that the development of knowledge stocks is lesser in absence of cooperation and commitment, i.e., when the learning process is by imitation. Furthermore, imitation can be associated with a incremental innovation that determine a lower development of knowledge than the case of interaction that can be develop radical innovation.
As to cognitive proximity, effective learning by interaction is accomplished by maintaining a sufficient cognitive distance while securing some cognitive proximity (stylized fact 4), thus, an inverted “U” relationship is used to model the relationship between learning by interaction (ΔKij,interaction) and cognitive distance.
otherwise, ΔKij,interaction = 0. Note that d is the geographical distance between the agents i and |Kj-Ki| is the cognitive distance (dc) between the agents i and j.
The relation between learning by imitation and development of the knowledge stock is modeled on the basis of the stylized fact 5. In particular, we use the following functions:
otherwise ΔKij,imitation = 0.
Figure 1 depicts the two functions where α = 1/2 , β = 3, δ = 1.2, γ = 1/4 and Ki = 1000. These values have been chosen to observe the desired behaviors within the definition intervals of the functions. The definition intervals of the functions depend on the size of the simulation grid and on the initial knowledge stock of the population. Given a rectangular grid 200x200, we chose parameters so as to have a function quickly declining with d. Moreover, given an initial knowledge stock of the population equal to 1000, we opportunely selected the parameters.
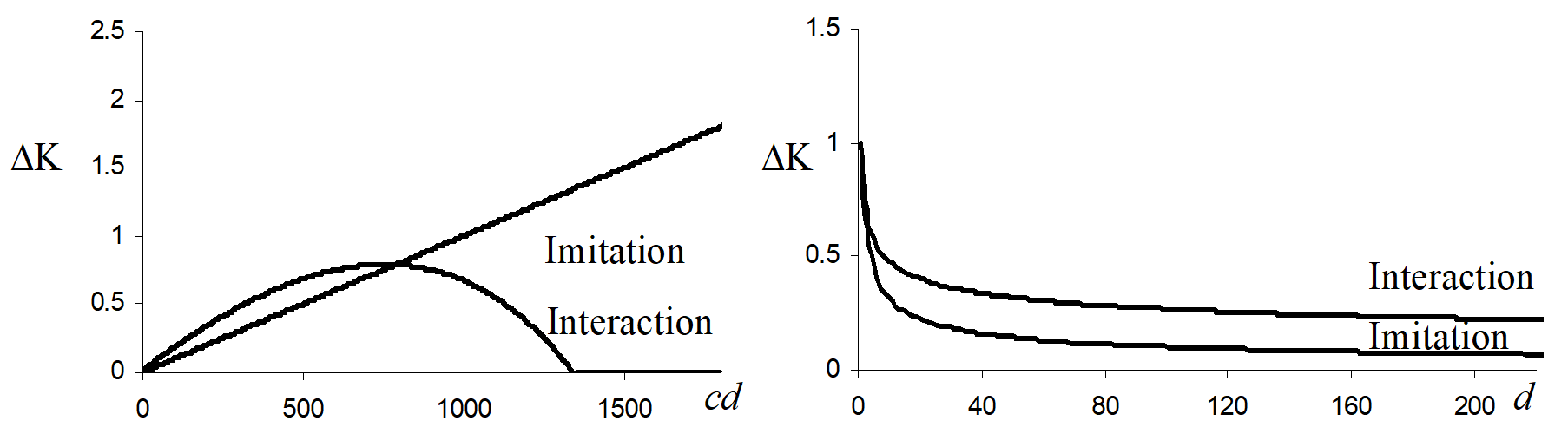
Figure 1: The influence of cognitive and geographical distances on ΔK
The absorptive capacity of the agent i when it interacts with j (Aij) is so computed:
According to this function, the absorptive capacity is a number between 0 and 1 and is highest for the agent with the highest knowledge stock and depends on the cognitive proximity between agents, coherently with the stylized facts 6 and 7.
The final expression of the development of the knowledge stock for the agent i when it interacts with j is the result of learning by imitation learning by interaction, and the agent's absorptive capacity. It is calculated as follows:
Developing knowledge stock. As a consequence of learning activities, each agent increases its knowledge stock. Given that learning is a cumulative process, at each step the value of Ki is updated by adding the quantity of knowledge stock resulting from the learning by imitation and learning by interaction. Thus, the knowledge stock of the agent i is updated as follows:
Choosing the new position. At each step each agent i selects a position in the grid among the possible adjacent cells (Figure 2). The agent will choose the position that maximizes the CAi.
Therefore, the agent computes the CAi for every new position included the current one and then chooses the position that assures the highest value. Therefore, the new position is so determined:
Pi,t+1 (x,y) = g ϶’ CAi(g) = Max {CAi(1), …, CAi(8), CAi(Pi,t)} (7)
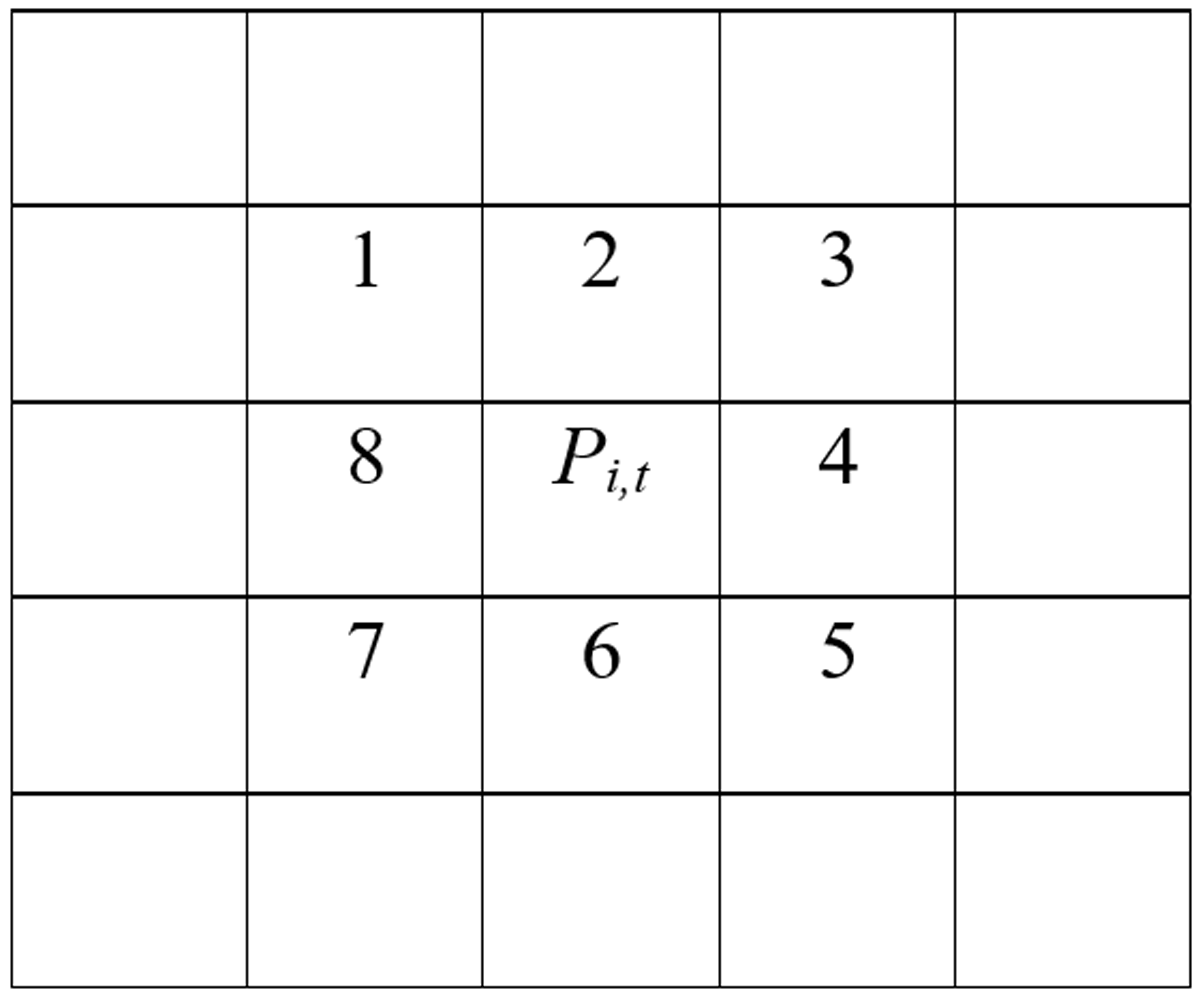
Figure 2: Possible new positions of the agent in the grid
Moving to the selected position. At each step the agent moves into the new selected position.
Measures
The emergence of spatial clusters. Spatial clusters of agents will emerge from a random spatial distribution of agents when the agents that move on the grid searching for their preferred position assume a stable position, and are arranged in groups of two or more agents. In this situation agents have no incentive to change their position. On the contrary, a clustering behavior does not emerge when agents continuously move around on the grid and/or assume a stand-alone stable position.
Description of the pattern of spatial clusters. Once spatial clusters have emerged, it is interesting to be able to rely on measures that describe the emergent pattern of the clusters. The characteristics of the pattern are assessed using the following measures: i) number of clusters, ii) average cluster size, iii) largest cluster size, and iv) smallest cluster size.
Knowledge development. We compute the following measures referring to the all population: i) average knowledge stock, ii) highest knowledge stock, iii) lowest knowledge stock. The same performances are also computed for each emerged cluster.
Sequencing of the events and simulation steps
At the start of the simulation, it is necessary to establish a specified number of agents and to assign characteristics to each agent, namely the starting position in the grid (randomly assigned) and the starting value of the knowledge stock (drawn at random from a uniform distribution).
Subsequently, the simulation is updated according to the following steps:
- Compute for the agent i the value of CAi for all possible new positions including the current one;
- Choose the position that maximizes CAi;
- Move agent i into the new position;
- Update the value of Ki;
- Repeat actions (a) through (d) until all agents have gone through that process;
- Repeat steps (a) through (d) for as many simulated time steps as specified;
- Compute the measures.
The number of simulation time steps is defined by assuming a value great enough to assure the emergence of spatial clusters of agents as a stationary state.
Simulation analysis
Plan of experiments
We ran the model with 30 agents located in a grid 200x200. In particular, the dimension of the grid has been chosen large enough to give all the agents the opportunity to choice the best location and the number of agents has been fixed to observe the emergence of spatial clusters in the grid.
Agents are randomly positioned on the grid and are characterized by the starting knowledge stock (Ki,0), which is drawn at random from a uniform distribution.
We conducted a comprehensive set of experiments to answer our research question. In particular, we planned experiments with increasing levels of the population heterogeneity. In particular, we defined several experiments characterized by the starting knowledge stocks (Ki,0) of the agents drawn at random from a uniform distribution with the same mean (1000) and an increasing standard deviation (see Table 1).
In all the experiments the simulation time was equal to 1000 and the number of replications was 100 (which differ for the initial spatial distributions of the agents). The simulation time has been chosen so long to observe a stationary state. We have started with lower simulation time and we have increased it until we noticed that after 1000 time steps agents assumed a stationary position into the grid. As to the number of replications, we noticed that the chosen number assures a reasonable compromise between the computational time and the ability to distinguish significant statistical differences among results in different settings (t-test).
| Level of heterogeneity | Starting knowledge stock (Ki,0) |
|---|---|
| Low | Uniform[990;1010] |
| Medium | Uniform[950;1050] |
| High | Uniform[800;1200] |
Table 1: Values of the parameters to define the experiments.
Simulation results
Results (Table 3) show a recurrent trend: in all the experiments spatial clusters of agents emerged within the simulation time. However, the important point about this and similar models is not that they generate a particular pattern of clusters, but that in every case, for a specific set of parameters, some degree of clustering always emerges (Gilbert, 2005).
To illustrate our results we first examine the performances of the experiment characterized by low heterogeneity of the population. This experiment in fact represents the baseline model through which we tested the internal validity of the model. In this case our findings confirm the expected behaviors because they show the emergence of spatial clusters of agents (see first column in Table 3). Then, we compare the results of the baseline model with those of the experiments characterized by increasing heterogeneity of the population (Table 3). Notice that when we compare the results, in each instance, the difference in mean performance is statistically significant with p < 0.001.
The baseline model
It represents the typical agglomeration of firms belonging to the same industry and characterized by similar knowledge assets (low level of heterogeneity). Thus, the baseline model corresponds to the experiment 1 in Table 3. It is run with the aim at verifying that the simulation model is able to reproduce the expected behaviors conforming to the empirical evidence and the conventional wisdom. What matters is not to examine the emergence of a particular pattern of clusters, whilst finding out some particular and expected relations between the main variables of the models. Thus, we analyze the simulation results in this respect.
Our results confirm that in this particular setting the agents tend to geographically cluster. In particular, even though there are an average 6.1 clusters, the biggest cluster includes the 36% of population, whilst the other clusters are smaller in size.
A further behavior we expected is that the more the agents tend to cluster, the more they develop knowledge. To verify that our model reproduced this behavior, we performed a regression analysis between the average knowledge stock of the agents in the cluster and the cluster size. Results shown in Table 2 confirm the existence of a positive relation between the two variables. Thus, to be part of a larger cluster increases the likelihood to develop knowledge thanks to learning by imitation and interaction.
| Multiple R | 0.788 |
| R2 | 0.619 |
| F | 388.987 |
| Sign. F | <0.001 |
| Intercept | 1085.734 |
| B | 57.953 |
| T | 19.723 |
| P | <0.001 |
Table 2: Regression analysis between the average knowledge stock and the cluster size.
The same behavior is also confirmed by Figure 3, where the average knowledge stock of the agents in the cluster is shown per cluster size. As the cluster size increases, the average knowledge stock of the agents in the cluster raises.
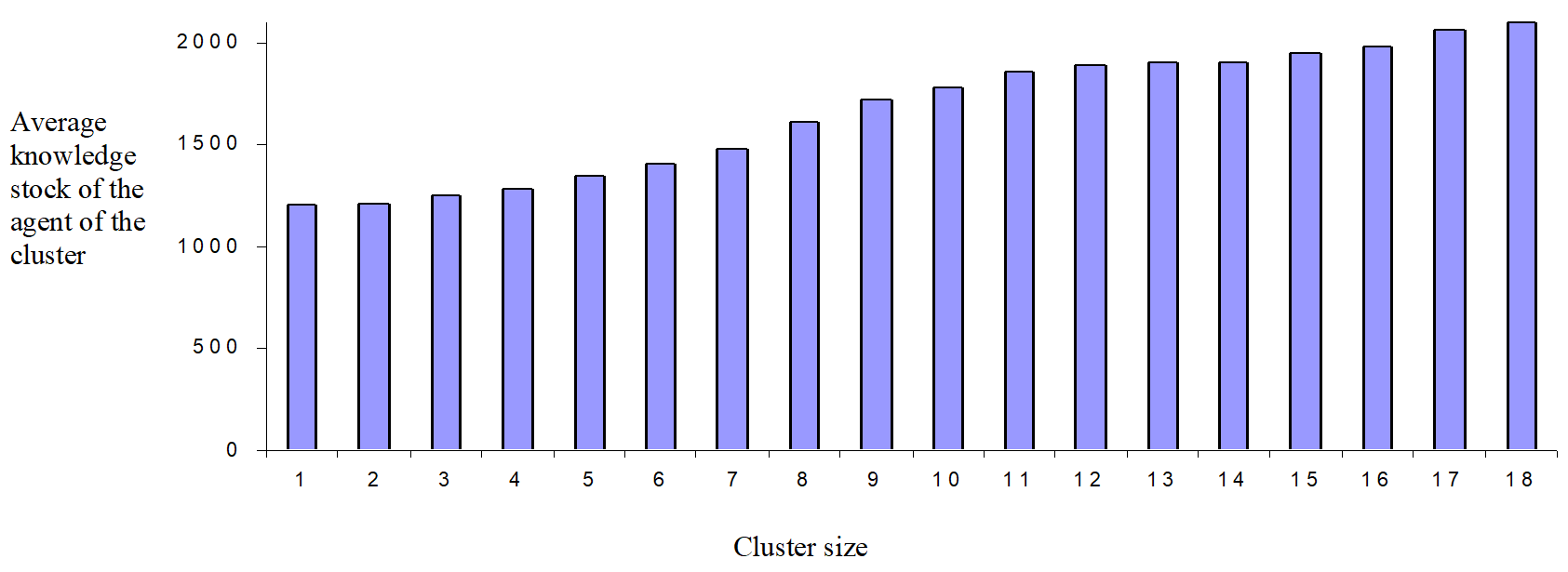
Figure 3: Average knowledge stock of the agents per cluster size in the case of the baseline model
It is also interesting to in deep analyze the emerged clusters in terms of developed knowledge stock. For each simulation we calculated for each cluster the average knowledge stock of the agents, the highest knowledge stock of the cluster, and the lowest knowledge stock of the cluster.
The difference between the highest and the lowest knowledge stock is a measure of the maximum cognitive distance between the agents in the cluster. The average value of the cognitive distance between the agents in the cluster is 449.7. Notice that it is considerably lower than the difference between the highest knowledge stock and the lowest knowledge stock of the population (2867). Such a result is consistent with our assumption: neither too much nor too few cognitive proximity is beneficial for the development of the knowledge stocks, thus the agents characterized by a moderate value of cognitive distance tend to be clustered.
As the cluster size increases, the cognitive distance increases. This means that the smallest clusters are characterized by agents more homogenous in terms of knowledge stock and the biggest clusters are more heterogeneous. They in fact are made up of a few agents with high knowledge stocks and a great number of firms with low knowledge stocks. The agent with the highest knowledge stocks always belongs to the biggest cluster, while the agent with the lowest knowledge stock belongs to the smallest clusters. The lowest knowledge stock reached in the biggest cluster is always higher than the lowest knowledge stock of the population.
Our results also show that both high and low knowledge intensive agents benefit from co-location. While this result is expected for the low knowledge agents, it is more interesting as to the high knowledge agents. Firms with high knowledge stocks benefit from being co-located with less knowledge firms because the possibility to interact with these firms permit them to develop an amount of knowledge stocks that is higher than the amount of knowledge stocks that is imitated by the low knowledge firms.
In summary, simulation results confirm that knowledge externalities motivate firms to form GCs. Agents prefer to be co-located rather than scattered, because in clusters they can improve their competitive advantage based on knowledge stock. Note that clusters emerge as the spontaneous results of each individual agent's decisions, so agents form clusters because this spatial configuration enhances their learning and consequently their knowledge stocks.
The influence of heterogeneity
To examine the influence of heterogeneity, we compared the results of the experiments in Table 3.
| Exp 1 | Exp2 | Exp 3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Heterogeneity | K |
K |
K |
||||||
| Mean | Std | VC | Mean | Std | VC | Mean | Std | VC | |
| Number of clusters | 6.1 | 1.5 | 0.24 | 7.2 | 1.3 | 0.18 | 8 | 1.1 | 0.14 |
| Average cluster size | 5.2 | 1.3 | 0.2 | 4.5 | 1.4 | 0.31 | 3.9 | 0.6 | 0.15 |
| Largest cluster size | 10.9 | 3.4 | 0.31 | 9.1 | 2.8 | 0.31 | 7.8 | 2.2 | 0.28 |
| Smallest cluster size | 2.4 | 1.1 | 0.45 | 2.2 | 0.9 | 0.41 | 2 | 0.3 | 0.15 |
| Highest knowledge stock | 4053.4 | 1302.1 | 0.32 | 4596.6 | 965.3 | 0.21 | 5197.7 | 1315.6 | 0.25 |
| Average knowledge stock | 1480.4 | 174.5 | 0.12 | 1850.5 | 203.6 | 0.11 | 2271.2 | 157.9 | 0.07 |
| Lowest knowledge stock | 1186.5 | 56.9 | 0.05 | 1435.7 | 100.5 | 0.07 | 1697.1 | 57.8 | 0.03 |
Table 3: The influence of the heterogeneity
Findings show that when firms are more heterogeneous, they are lesser willing to be co-located. In fact, as the heterogeneity increases, the number of clusters increases, the average cluster size diminishes as well as the smallest and the largest decreases. Agents tend to form more groups of smaller sizes. The largest cluster that in the case of low heterogeneity included the 36% of the population, when the heterogeneity becomes very high contains about the 25% of the population.
Agents are less willing to be co-located because a high level of heterogeneity increases the cognitive distance between agents, which in turn raises the development of knowledge stock due to learning by interaction and to learning by imitation. Thus, the agents can obtain increases of knowledge stocks thanks to higher cognitive distance even though they are locate at a high distance.
Nevertheless, a clustering behaviour always emerge and there is a positive relationships between the average knowledge stock of the agents and the cluster size, confirmed by regression analyses not reported here.
An interesting result is shown in Figure 4, where the average knowledge stock of the agents in the cluster is shown per cluster size. When heterogeneity increases, the isolated agent (cluster size equal to 1) tend to reach a better performance than firms in small-sized clusters. To be isolated is more beneficial than to belong to small clusters. In other words, only if the cluster reaches a critical mass it becomes beneficial to be part of a cluster.
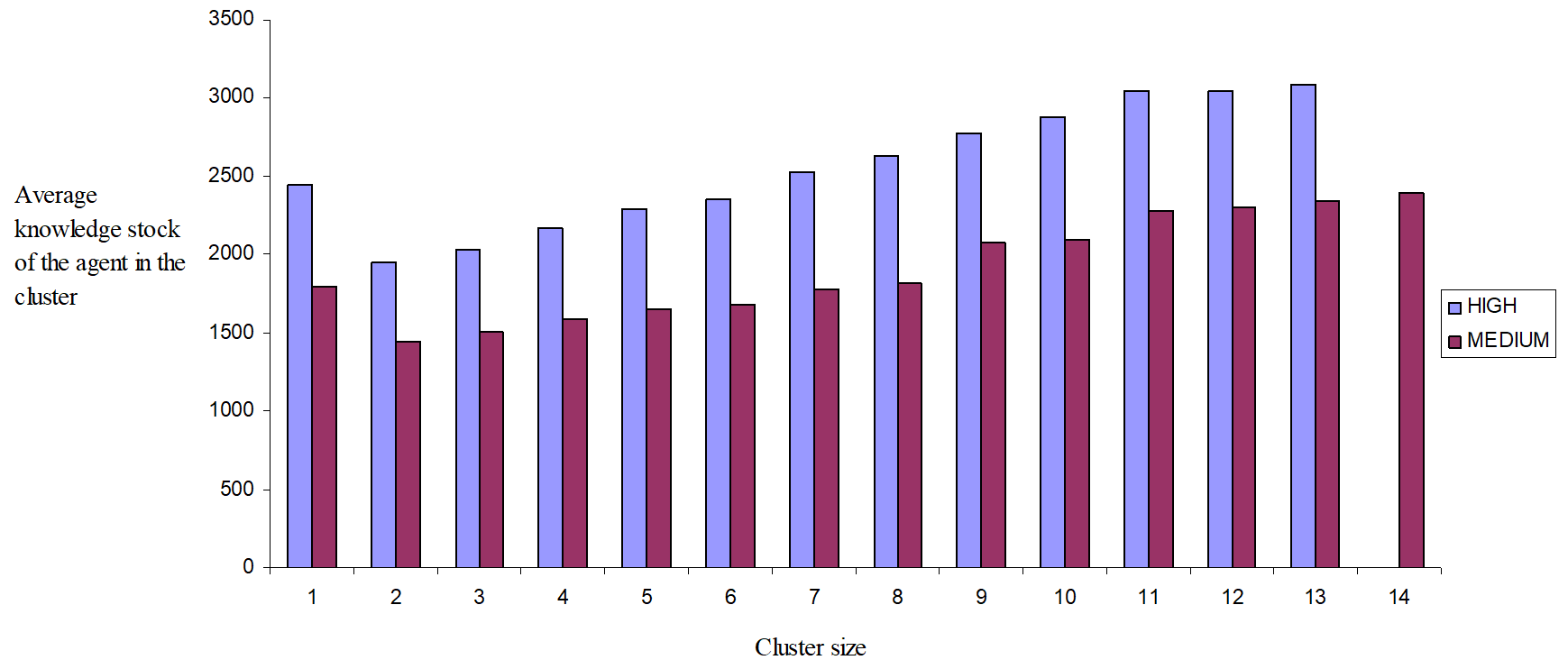
Figure 4: Agent average knowledge stock per cluster size in the case of increasing heterogeneity
With regard to the knowledge performances, the average, the highest, and the lowest value of knowledge stock of the population increases with the heterogeneity. As observed before, a higher heterogeneity increases the development of knowledge stocks due to learning by interacting and to learning by imitation. Heterogeneity is thus a source of knowledge and increases the level of knowledge of the population. This result is consistent with the studies that recognize the importance of heterogeneity in innovation and knowledge creation (Allen, 2001).
However, the increased average level of knowledge does not generate a more intense process of geographical clustering, while on the contrary pushes firms to be less willing to be co-located. A different source of knowledge externalities is acting, namely the heterogeneity in the knowledge stock of the agents that does not require physical proximity among firms.
In summary, the heterogeneity decreases the willingness of firms to be co-located and is a source of knowledge development. Firms however prefer to be co-located (even though in clusters of smaller size) rather than scattered.
Robustness
We tested the robustness of our simulation model by conducting a greater set of experiments than those reported here and we observed the same qualitative patterns of results.
Alternative functional specifications of equations 2 and 3 have been tested. What we have noticed is that whatever the form of the functions a geographical clustering behavior always emerges, while the form of the functions mainly influences the speed of the process. Given that a very large number of options are available, what matters is that the decline is within the definition interval of the geographical distance. When the learning function stays stable within the definition interval we did not observe any cluster agglomeration.
We tested the robustness of the model also with different initial conditions, i.e. the number of agents and the form of the distribution of the starting knowledge stock of the agent. The results we observed did not vary in qualitative terms when the number of agents increases and the Gaussian distribution is used.
Conclusions
This paper has examined the concept of knowledge externalities in agglomeration economies, namely the knowledge-based benefits that co-located firms can gain and that motive them to form geographical clusters (GCs). These are now receiving renewed attention because in a knowledge-based economy competitive success is related to the ability of firms to create and increase their knowledge rather than pursuing static efficiency.
Knowledge externalities have been associated with two specific learning processes, and have been analyzed by adopting the firm-level perspective, thereby filling two gaps in the literature, namely little study of the central role of learning in clustering process and a prevailing tendency to adopt a system-level perspective. We have considered that firms can benefit due to learning by imitation and learning by interaction. The extent to which these learning processes develop knowledge stocks is influenced by two dimensions of proximity, namely the geographical and the cognitive proximity.
Moreover, we analyzed the geographical clustering process as the spontaneous result of the firm location choice according to recent strategic management orientations that consider the location choice a strategic decision. In particular, firms choose the location that maximize the net knowledge spillovers, i.e., the difference between the inward spillovers and the outward spillovers.
The specific aim of the paper has been to examine how the firm heterogeneity affect the geographical clustering process. In fact, so far literature and empirical evidence do not provide a conclusive answer to this regard.
To pursue our aim we have adopted an agent-based simulation. This approach is particularly valuable because it permits GCs to be studied as complex adaptive systems of interacting agents. In particular, we considered that it is the agent's individual decisions and the interactions among the agents that determine the emergence of the geographical cluster itself.
An agent-based model has been developed where agents (firms) located in a grid have to maximize their competitive advantage by choosing a new location in the environment that assures them the highest net benefits in terms of knowledge stock. The development of knowledge stock depends on both the interactive learning processes and the agent's absorptive capacity. The effectiveness of learning by imitation and interaction in terms of increased knowledge stock is influenced by geographical and cognitive distances among agents.
A simulation analysis has been finally carried out to evaluate the influence of the heterogeneity. The results have shown that the geographical clustering process is influenced in terms of the emergent pattern of clusters and the development of knowledge stocks.
When there is notable heterogeneity, agents tend to form more groups of smaller size and are characterized in average by higher level of knowledge stocks. An important finding of this paper is that when firms are homogenous in terms of knowledge they tend to be co-located more than when they are heterogeneous, because heterogeneity enhances learning opportunities regardless to geographical proximity. Heterogeneity is a source of knowledge because it increases the cognitive distance between firms that in turn raises the development of knowledge stocks due to learning. Thus, firms are less willing to be co-located.
This result could explain because in some industries GCs are larger in size than in other ones. For example, the Italian Industrial Districts that are widespread in different sectors widely vary by number of firms. Our results suggest that this pattern could depend on the level of heterogeneity of the firm knowledge stocks within the industrial sectors. Sectors characterized by firms with quite homogenous knowledge (e.g. mature industries) will show an organization in clusters larger in size; while sectors with firms more heterogeneous in knowledge (e.g. high-tech industries) will be arranged in small-sized clusters. In the first case the physical proximity is the most important mechanism to enhance learning and knowledge development. In the second case the cognitive distance is the key to improve the learning opportunities.
Moreover, we found that the emerged clusters are characterized by the existence of few high knowledge agents and a greater number of low knowledge agents. Thus, our findings suggest that not only the low knowledge intensive firms benefit from co-location but also the high ones. In particular, we found that the high knowledge intensive firms benefit from co-location when they are co-located with a number large enough of low knowledge intensive firms, because the possibility to interact with these firms permit them to develop an amount of knowledge stocks that compensates the knowledge spilling over to low knowledge firms. This result is confirmed by the empirical evidence of some successful Italian Industrial Districts characterized by the existence of few firms having a leader position in terms of resources and knowledge in the district and a large number of small firms with scarce assets.
Policy implications to enhance knowledge development can be formulated on the basis of our findings. First of all, heterogeneity should be promoted because it increases the knowledge development of the firms. For example, it is better to invest in the improvement and the strengthening of few high knowledge firms (e.g., the leader firms in the Italian Industrial Districts) rather than to support all firms. Furthermore, the innovation policies should be fine-tuned according to the level of sector heterogeneity. When the sector is made up of firms quite homogeneous in terms of knowledge, co-location should be promoted. When in the sector there is knowledge heterogeneity, the ways of interaction among firms should be promoted. Thus, we believe that to improve the knowledge development and innovation in a high heterogeneity sector, such as the mechatronic one, the clustered organization is not necessary, while it is more important to design for firms the opportunities and the tools to interact each other even though they are located at a distance. These opportunities to interact could be favored by means of financial support to joint research projects or to sector associations and consortia; the tools to interact could be promoted by supporting the buy of ICT-based solutions such as groupware technologies as well as by promoting the birth of a sector portal where firms can communicate each other.
Our model presents some limitations. It considers knowledge externalities associated with two specific GC learning processes. In some industries, however, collective learning may be more representative of innovation diffusions than the considered learning processes. Therefore, we should also introduce this learning process in the agent-based model. Furthermore, we do not distinguish between tacit and codified knowledge even though the transfer process of the two kinds of knowledge may differ. For example, the tacit knowledge to be transferred requires a geographical proximity much more than codified knowledge does. The various dimensions of proximity may influence the learning of tacit and codified knowledge in different ways. Investigating in this direction could be an interesting successive step of the research. The knowledge stock of firms also needs to be better modeled. Different kinds of knowledge stocks should be introduced to distinguish agents not only in terms of the amount of knowledge stock but also of the kind of knowledge stock they posses (for example in manufacturing, in marketing, and so on). Further attributes characterizing the firm should be added, for example the resources, the products, and the markets. This would allow the strategic behavior of the firm to be better modeled.
Further limitations regard the proximity included in the model. We consider only geographical and cognitive proximity but we are aware that organizational, social and institutional proximity also play a key role in interactive learning. In particular, we think the influence of organizational proximity should be much more closely investigated because it could be useful to explain some recent changes that GCs are undergoing, such as the emergence of firms taking a leader position. In the next step of the research we will include the influence of organizational proximity on the learning processes. In this regard, a further extension of our model will be to introduce the different dimensions of proximity and examine which out of the possible combinations of proximity determine geographical clustering. The relationships between the various proximities can also be investigated.
Finally, we use specific relationships between learning and proximity. Most have been based on the literature but others have been assumed because to our knowledge there is no evidence in the literature. Thus, the assumed relationships should be validated by empirical research (external validity).
Footnote
References
Albino, V., Carbonara N. and Giannoccaro I. (2003). "Innovation within industrial districts: An agent-based model," International Journal of Production Economics, ISSN 0925-5273, 1: 30-45.
Albino, V., Carbonara N., and Giannoccaro I. (2006). "Coordination mechanisms based on cooperation and competition within industrial districts: An agent-based computational approach," Journal of Artificial Society and Social Simulation, ISSN 1460-7425, 3(4)
Alcacer, J. (2006). "Location choices across the value chain: How activity and capability influence collocation," Management Science, ISSN 0025-1909, 10: 1457-1471.
Alcacer, J. and Chung, W. (2007). "Location strategies and knowledge spillovers," Management Science, ISSN 0025-1909, 5: 760-776.
Allen, P.M. (2001). "A complex systems approach to learning, adaptive networks," International Journal of Innovation Management, ISSN 1363-9196, 5: 149-180.
Audretsch D.B., Lehmann E., and Warning S., (2005). "University spillover and new firm location," Research Policy, ISSN 0048-7333, 5: 1113-1122.
Audretsch, D.B. and Feldman, M.P. (1996). "R&D spillovers and the geography of innovation and production," The American Economic Review, ISSN 0002-8282, 3: 630-640.
Axelrod, R. (1997). "Advancing the art of simulation in social sciences," in R. Conte, Hegselmann, R., and Terna, P. (eds.) Simulating Social Phenomena, ISBN 9783540633297.
Baptista, R. (2000). "Do innovations diffuse faster within geographical clusters?" International Journal of Industrial Organization, ISSN 0167-7187, 18: 515-535.
Belussi, F. and Arcangeli, F. (1998). "A typology of networks: flexible and evolutionary firms," Research Policy, ISSN 0048-7333, 4: 415-428.
Boschma, R. (2005). "Proximity and innovation: a critical assessment," Regional Studies, ISSN 0034-3404, 1: 61-75.
Breschi S. and Lissoni F. (2001). "Knowledge spillovers and Local Innovation Systems: A critical survey," Industrial and Corporate Change, ISSN 0960-6491, 10: 975-1005.
Camagni R. (1995). "Global network and local milieu: Towards a theory of economic space." in S. Conti, E. Malecki & P. Oinas (eds.), The Industrial Enterprise and Its Environment: Spatial Perspectives, ISBN 9781856288767, pp. 195-214.
Capello R. and Faggian A. (2005). "Collective learning and relational capital in local innovation processes," Regional Studies, ISSN 0034-3404, 1: 75-87.
Carbonara N., Giannoccaro I., and McKelvey B. (2006). "Making geographical clusters more successful: Complexity-based policies," Emergence: Complexity & Organization, ISSN 1521-3250, 12: 21-45,
Cohen, W. and Levinthal, D. (1990). "Absorptive capacity: A new perspective on learning and innovation," Administrative Science Quarterly, ISSN 0001-8392, 35: 128-152.
Cohendet, P. and Llerena, P. (1997). "Learning, technical change, and public policy: How to create and exploit diversity," in C. Edquist (ed.), Systems of Innovation. Technologies, Institutions and Organizations, ISBN 9781855674523.
Davis J.P., Eisenhardt K.M., Bigham, C.B. (2007). "Developing theory through simulation methods," Academy of Management Review, ISSN 0363-7425, 32: 480-499.
Decarolis, D.M. and Deeds, D.L. (1999). "The impact of stocks and flows of organizational knowledge on firm performance: An empirical investigation of the biotechnology industry," Strategic Management Journal, ISSN 0143-2095, 20: 953-968.
Ernst, D. (2002). Global production networks and the changing geography of innovation systems: Implications for developing countries. Economic Innovation and New Technology, ISSN 1043-8599, 6: 497-523.
Gertler, M.S. (1995). "Being there: Proximity, organization and culture in the development and adoption of advanced manufacturing technologies," Journal of Economic Geography, ISSN 1468-2702, 71: 1-26.
Giannoccaro I., (2015). "Adaptive supply chains in industrial districts: A complexity science approach focused on learning," International Journal of Production Economics, ISSN 0925-5273, 170: 576-589.
Gilbert N. (2005). Agent-Based Simulation: Dealing With Complexity, link
Giuliani E. (2007). "The selective nature of knowledge networks in clusters: evidence from the wine industry," Journal of Economic Geography, ISSN 1468-2702, 2: 139-168.
Giuliani E. and Bell M. (2005). "The micro-determinants of meso-level learning and innovation: evidence from a Chilean wine cluster," Research Policy, ISSN 0048-7333, 1: 47-68.
Grant, R.M. (1997). "The knowledge-based view of the firm: Implications for management in practice," Long Range Planning, ISSN 0024-6301, 3: 450-454.
Hamel, G. and Prahalad, C.K. (1994). Competing for the Future, ISBN 9780875847160.
Howells, J.R.L. (2002). "Tacit knowledge, innovation and economic geography," Urban Studies, ISSN 0042-0980, 39: 871-884.
Jaffe A.B., Trajtenberg M., and Henderson R. (1993). "Geographic localization and knowledge spillovers as evidence by patent citations," Quarterly Journal of Economics, ISSN 0033-5533, 108: 577-598.
Keeble, D., Lawson, C., Moore, B., and Wilkinson, F. (1999). "Collective learning processes, networking and 'institutional thickness' in the Cambridge region," Regional Studies, ISSN 0034-3404, 33: 319-331.
Krugman, P.R. (1991). Geography and Trade, ISBN 9780262111591.
Leonard-Barton, D. (1995). Wellsprings of Knowledge, ISBN 9780875848594.
Malerba F. (1992). "Learning by firms and incremental technical change," The Economic Journal, ISSN 1468-0297, 845-859.
Marshall, A. (1920). Principles of Economics, ISBN 9780230249295.
Maskell, P. (2001a). "Towards a knowledge-based theory of the geographical cluster," Industrial and Corporate Change, ISSN 0960-6491, 10: 921-943.
Maskell, P., (2001b). "Knowledge creation and diffusion in geographical clusters, international," Journal of Innovation Management, ISSN 1363-9196, 2: 213-237.
Noteboom B., Van Haverbeke, W., Duysters, G., Gilsing, V., and van den Oord, A. (2007). "Optimal cognitive distance and absorptive capacity," Research Policy, ISSN 0048-7333, 4: 1016-1034.
Pinch, S., Henry, N., Jenkins, M., and Tallman, S. (2003). "From 'industrial districts' to 'knowledge clusters': A model of knowledge dissemination and competitive advantage in industrial agglomerations," Journal of Economic Geography, ISSN 1468-2702, 3: 373-388.
Piore, M. and Sabel, C.F. (1984). The Second Industrial Divide, ISBN 0465075614, New York: Basic Books.
Porter, M. (1998). "Clusters and the new economics of competition," Harvard Business Review, ISSN 0017-8012, 6: 77-90.
Pouder, R. and St. John, C.H. (1996). "Hot spots and blind spots: Geographical clusters of firms and innovation," Academy of Management Review, ISSN 0363-7425, 4: 1192-1225.
Rivkin, J.W. (2000). "Imitation of complex strategies," Management Science, ISSN 0025-1909, 824-844.
Shaver, M.J. and Flyer, F. (2000). "Agglomeration economies, firm heterogeneity, and foreign direct investment in the United States," Strategic Management Journal, ISSN 0143-2095, 21: 1175-1193.
Siggelkow, N. and Rivkin, J.W. (2005). "Speed and search: Design organizations for turbulence and complexity," Organization Science, ISSN 1047-7039, 101-122.
Spender, J.C. (1996). "Making knowledge the basis of a dynamic theory of the firm," Strategic Management Journal, ISSN 0143-2095, 17: 45-62.
Tallman, S., Jenkins, M., Henry, N., and Pinch, S. (2004). "Knowledge, clusters, and competitive advantage," Academy of Management Review, ISSN 0363-7425, 2: 258-271
Tesfatsion, L. and Judd K. (eds.) (2006). Handbook of Computational Economics, ISBN 9780444512536.
van Canneyt M. and Klampfe F. (2005). User's Manual of Free Pascal, link