A cognitive interpretation of organizational complexity
Guido Fioretti
University of Bologna, ITA
Bauke Visser
Erasmus University, NLD
Abstract
Organizational theory has construed complexity as an objective characteristic of either the structure or the behavior of an organization. We argue that, in order to further our understanding, complexity should be understood in terms of the human cognition of a structure or behavior. This cognitive twist is illustrated by means of two theoretical approaches, whose relationship is discussed.
Introduction
Organization theory presents complexity as an objective property of the organization, much in the same way as, e.g., its degree of centralization and formalization. It is viewed as an objective characteristic of the structure of an organization, defined and measured in terms of the number of its constituent parts, their diversity and relationships (e.g., Lawrence & Lorsch 1967; Thompson, 1967; Galbraith, 1973; Jablin, 1987; Daft 1989). In the 1990s, complexity also became identified with intricate organizational behavior, with small changes at the unit or employee level, possibly giving rise to ‘complex’ aggregate patterns (e.g., Anderson, 1999; Lissack, 1999a, 1999b; Marion, 1999).
The aim of this paper is to argue that complexity should neither be defined nor measured in term of its source, be it an obj ectively given feature of the structure or of the behavior of an organization, but instead in terms of its effects on human cognition. Organization theorists have been careful in pointing to the decision context within which the concept of complexity plays a role. Briefly, complexity as numerosity, diversity, and unpredictability matters because of the increasing demands it imposes on decision makers concerned with attaining overall organizational effectiveness. But such demands are cognitive in nature. It therefore only seems natural to take the analysis one step further by detaching the notion of complexity from its objective source and instead attaching it to its consequence on the cognitive effort exerted by the decision maker to come to grips with her decision problem. That is, an organization is complex to the extent that a human being - e.g., an organizational designer or an outside observer - has to exert a certain degree of cognitive effort in coming to grips with a decision problem.
Various reasons support this cognitive turn. First, this approach fits well with the general outlook of the theories in which the objective notions of complexity appear. As noted, complexity as a structural feature figures within well-defined decision theoretic approaches to organizations, and it therefore seems natural to construe complexity cognitively. The same applies to behavioral complexity. Second, it helps unify existing organization theory. In particular, we illustrate how this approach may shed light on the discussion of whether structural complexity stems from the number of horizontally organized units and vertically organized layers, or from the connections between these parts. Moreover, it helps show commonalities between theories focusing on complex behavior and theories focusing on complex structures. Third, it is in line with major accounts of complexity in general. Finally, a cognitive approach is in line with what one commonly understands to be ‘complex’. “This is complex” is an utterance typical in situations when we do not understand something, as is clear from the fact that without any change in the observed phenomenon or the problem at hand, all at once we may consider it trivial or at least manageable.
After an overview of the main ingredients of contemporary thought on complexity in the realm of organization theory, the cognitive turn is presented in general terms. In the section titled “What a decisionmaker does not know...”, the first operationalization is presented that starts with the cognitive map held by a human being who faces an organizational problem. Complexity is defined in terms of the level of dissatisfaction with the explanatory power of a cognitive map. The second operationalization, discussed in the section titled “...And what a decision-maker should know”, defines complexity in terms of information required to solve an organizational problem. An application to the problem of selecting projects by a firm illustrates its main features. The relationships between these two approaches are discussed in the concluding section.
The traditional approach to organizational complexity
There are two strands in the organizational literature that use the words ‘complex’ and ‘complexity’ to characterize organizations. The first one refers to structural features of an organization. In particular, an organization is called complex if it is large and consists of several subsystems (e.g., R&D, manufacturing, sales, finance) that differ from each other “in terms of subsystem formal structures, the member’s goal orientation, member’s time orientations and member’s interpersonal orientations” (Lawrence & Lorsch, 1967: 1). Thompson (1967: 55-59) and Galbraith (1973: 46-66) characterize a complex organization very much in the same vein. These authors stress the importance of the relationships among organizational units as being at the root of complexity.
With a slightly different emphasis, Jablin and Daft focus on the number of organizational parts in their definitions of complexity. Jablin (1987) uses complexity to depict “the structural components/units into which organizations and their employees may be categorized”. He distinguishes vertical and horizontal complexity. Vertical complexity is the outcome of vertical differentiation and “is an indication of the number of different hierarchical levels in an organization relative to its size.” Similarly, horizontal complexity measures “the number of department divisions in an organization.” One such measure is the “number of different occupational specialities or specialized subunits at a given hierarchical level.” That is, complexity refers to the number of parts in an organization, with each part specializing in some activity. Daft (1989: 18) uses very similar definitions.
In this line of research, complexity matters because the implied differentiation allegedly requires integration for the organization to perform well. Lawrence and Lorsch (1967: 1) consider differentiation and integration to be antagonistic states, and study ways in which organizations assure integration. Thompson and Galbraith observe that differentiation and heterogeneity make coordination necessary, with the intensity of coordination being dependent on the type of interdependence. They come up with a classification of complexity on the basis of these differences in the intensity of coordination and the ensuing differences in information processing demands. Thompson (1967: 55-59) distinguishes pooled, sequential, and reciprocal interdependencies between subsystems as the basis for his classification of degrees of complexity. Galbraith, (1973) distinguishes lateral relationships of varying intensity. Types of coordination differ in communication and decision load, and Thompson (1967: 56) adds, “[t]here are very real costs involved in coordination.”
Since the end of the 1980s, a second strand in the literature on organizations has emerged that uses the notion of complexity. Here, it is related to the behavior originating from the interactions of the many parts of a ‘complex’ system. Building upon early studies on self-organization (Nicolis & Prigogine, 1977; Prigogine & Prigogine, 1989; Haken, 1983, 1987), several models investigated the formation of structures between a large number of interacting particles and the ensuing properties of the behavior of the system as a whole (Fontana, 1991; Kauffman, 1993). By analogy, one started to suspect that similar phenomena were widespread in natural and social systems alike. Complexity came to be identified with a special kind of behavior, i.e., with intricate aggregate patterns emerging from the interaction of the constituent parts of an organization that themselves followed relatively simple behavioral rules. It is evident that these insights and their related methodologies are relevant to organizational problems (Anderson, 1999; Frank & Fahrbach, 1999; Lissack, 1999a, 1999b; Marion, 1999; Morel & Ramanujam, 1999).
According to this strand of literature, complexity matters to organization theory because it makes organizational behavior subject to surprises and hard to predict (Anderson, 1999: 216-217), rendering the attainment of organizational effectiveness nonobvious. Consequently, decision-makers should become aware of the limits of their knowledge and engage in a learning process with the complex system they are facing (Allen, 2000, 2001; Cilliers, 2002; Allen & Strathern, 2003). Indeed, complexity is not seen as a set of rules to solve a particular set of problems, but rather a perspective that may provide a new understanding to problems (Lissack & Letiche, 2002).
A cognitive turn
The shift from a view of complexity based on the number of component parts to the intricacy of microbehaviors to the current emphasis on the methodology of complexity suggests the possibility of a cognitive turn in the interpretation of this concept: from understanding organizational complexity in terms of the structure or the behavior of an organization to its effects on human cognition.
We want to argue that the very reason that makes complexity important to organizational theory also points to a cognitive conception of complexity. There is wide agreement that complexity matters because of the resulting difficulties when it comes to questions of organizational design and decision making. The multiplicity of subsystems, their diversity, the linkages among them, and the unpredictable aggregate behavior that results make designing ‘effective’ organizations and taking decisions involving organizations hard. That is, complexity matters only because of the cognitive problems it gives rise to. It is therefore only natural to define and measure complexity in cognitive terms.
In other words, this cognitive turn implies that complexity should not be seen as an objective feature of some organizational characteristic, but rather as relative to a decision problem or to the representation a decision maker has of this problem. Apart from being an arguably natural part of the organizational theories in which it plays a role, a cognitive conception of complexity has got three other advantages.
First, it sheds light on various questions that come up when studying the extant literature on organizational complexity, two of which will be presented here. Recall that in the literature on complexity as a feature of organizational structure, there was little agreement on the measurement of complexity. Some argued that complexity is captured by the number of horizontally arranged units and vertical layers, while others insisted on the type of connections between these units and layers. We illustrate in “...And what a decision-maker should know” how explicitly taking into account the cognitive requirements an organizational designer faces may resolve the dilemma of whether numbers or connections matter. A further ambiguity concerns the relationship between complexities as an aspect of organizational structure on the one hand, and complexity as organizational behavior on the other hand. Little has been said about their relationship, though in both cases reference is made to numerous parts that are somehow connected. What unites both approaches is the implicit assumption that numerosity and connectedness make understanding more complicated. Thus, moving to the level of cognition allows us to unify these two strands of literature.
Second, support for a cognitive view of complexity in the realm of organizational studies is provided by several conceptions of complexity in general, to begin with Dupuy, (1982) and Rosen, (1985) but also including Crutchfield and Young (1989) and Gell-Mann (1994), who moved from the idea of computational complexity (Solomonoff, 1964; Kolmogorov, 1965; Chaitin, 1966). These insights impact on a discipline where it is widely recognized that strategy-making is tightly linked to both cognitive and organizational problems (Anderson & Paine, 1975). So among organization theorists, Simon (1999: 215) directs our attention to complexity as a characteristic of a description instead of complexity as an objectively given characteristic: “[h]ow complex or simple a structure is depends critically upon the way in which we describe it”. Rescher (1998: 1) is even more explicit about the role of cognition in the definition of complexity. Writing within the context of complexity in general, he states “[o]ur best practical index of an item’s complexity is the effort that has to be expended in coming to cognitive terms with it in matters of description and explanation.”
Third, explicit recognition of the cognitive nature of complexity fits very well with the use of the word ‘complex’ in common parlance. Suppose one were to find a more cogent, less complicated account of some (organizational) phenomenon. Then, in common parlance, one would say that the phenomenon itself has become less complex. Even if a phenomenon is not changing one may consider it ‘complex’ at a certain point in time and ‘simple’ at a later time, if in the meantime sufficient information has been received and a proper reformulation of the problem allowed to come to grips with it.
In the next two sections, we provide two ways of exploring organizational complexity in a cognitive way. We illustrate how one could operationalize a cognitive approach to complexity in the realm of organization theory. The two models that we expound tackle the same problem from different sides and thus provide complementary points of view.
What a decision-maker does not know...
The first approach to operationalize a cognitive view of complexity starts from observing and modeling the way decision-makers represent problems in their minds. If this representation has been able to suggest the correct behavior, a decision-maker will not say that he is facing a complex reality. If, however, this representation suggested a behavior that induced an outcome very different from the intended one, then a decision maker may not be confident that s/he has framed the decision-problem in the best possible way. To the extent that he doubts his own representation of a decision problem, he will say that this is a complex one.
Let us look more closely at the process by which mental representations of decision problems arise. Options, objectives and strategies are not self-evident. Rather, they result from the cognitive processes of information categorization and the construction of causal relations between these categories; processes whose ultimate outcome is a cognitive map (Hebb, 1949; Hayek, 1952).
A cognitive map is a network of causal relationships between options and objectives that one can safely trust most of the time, if not always. The cognitive map of a company entails the options that it envisions, the objectives that it wants to pursue, and a network of causal links from options to objectives along paths that represent available strategies.
Corporate cognitive maps can be reconstructed by means of a linguistic analysis of letters to shareholders and other corporate documents (Sigismund-Huff 1990). For instance, Figure 1 illustrates a portion of Chrysler’s cognitive map extracted from speeches to securities analysts in 1976 (Sigismund-Huff & Schwenk, 1990).
Observing Figure 1 it is evident that, in 1976, standardization and reduction of parts were high on the agenda. For instance, “to reduce the total number of part numbers to about 50,000” is deemed to generate “additional productive capacity without a major investment in brick and mortar.” Here we can see a causal link from the option of reducing parts to the objective of increasing productive capacity, which, taken together with all other causal links, illustrates Chrysler’s strategy. Although Figure 1 also includes a number of equivalence relations and supportive examples, these are rhetorical devices that have been included in the speech with the purpose of stressing causal links. Ultimately, causal links constitute the backbone of a cognitive map.
Thus, the structure of a cognitive map can be seen as a set of links between options and objectives as depicted in Figure 2. Note that in order to draw Figure 2 from a part of Figure 1, options and objectives had to be compounded using the equivalence and example relations.
The most important fact about cognitive maps is that causal relations between options and objectives are not conceived independently of options and objectives themselves. For instance, the causal link between “reducing the number of parts” and “increasing profitability” was not conceived independently of the idea of reducing the number of parts and increasing profitability to the levels attained by Japanese competitors. In fact, managers define options by lumping a number of detailed actions at the shop-floor level into broad categories (e.g. “reducing the number of parts”). Similarly, they define objectives by lumping a number of accounting variables together (e.g., into “increasing profitability”). Options and objectives are mental categories for a number of actions to undertake and a number of indicators to observe, which are defined having in mind a possible causal link between them. Thus, the categories employed by a decision-maker cannot be investigated in isolation from one another, but rather within the network in which they are embedded.
Since causal links are tailored to specific options and objectives, emergence of novelties is detected when the chosen option did not reach the expected objective.
Figure 1 Chrysler cognitive map, 1976. Positive causal links are denoted by a ‘+’, negative causal links are denoted by a ‘-’, equivalences are denoted by a ‘=’ and 10 examples are denoted by an ‘e’. Dashed lines denote inferred relationships.
For instance, Chrysler’s experience after restructuring was that, although its reorganization program brought it close to the standards of its Japanese competitors, lack of standardized communication procedures kept it short from reaching their levels of performance (Sobek, et al., 1998). In other words, novelties call attention upon themselves because causal links appear, that are different from the expected ones. This observation is crucial for the concept of complexity presented in this section.
In fact, let us define complexity as the extent to which empirical experience runs contrary to the expectations embedded in a cognitive map. It is when novelties emerge that the causal relations that one expects may not hold. On these occasions, a decision-maker is likely to say that he is facing a ‘complex’ environment.
Given this definition, complexity can be measured by looking at the structure of causal links in a cognitive map. At a first glance, it may seem straightforward to measure complexity by means of an index of the extent to which empirical experiences make a cognitive map intertwined: the more distant from a simple network of one-to-one correspondences, the higher the complexity is. However, a second factor should be considered, namely, that a cognitive map where highly intertwined blocks are separated by sparse links should yield a lower complexity than one where even blocks are not distinguishable. For instance, Figure 3 illustrates a situation where complexity should be zero (left), maximum (center) and intermediate (right). In this last case, complexity is lower because intertwined causal links are arranged in blocks. Although Figure 1 does not depict a very intertwined cognitive map, we can distinguish blocks of linkages: the largest one refers to parts reduction and standardization, a second one focuses on the merger with a South African car manufacturer, and two other blocks are concerned with compact and midsize cars, respectively. A detailed mathematical account of the proposed measure can be found in Appendix A.
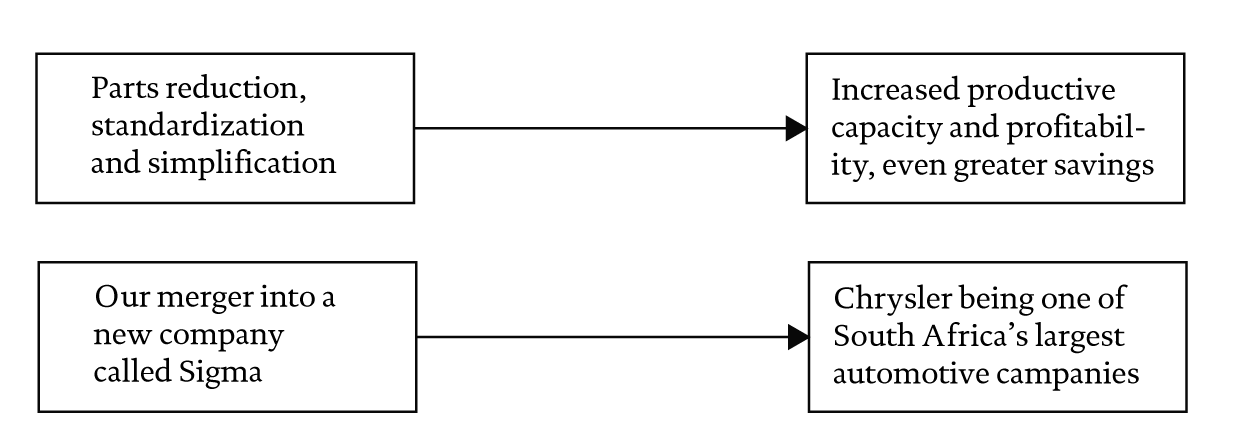
Figure 2 A portion of the causal links depicted in Agure1, after compounding some of the items
Figure 3 Three cognitive maps illustrating causal links between options and objectives From left to right, a cognitive map that works perfectly envisions a simple world, a cognitive map that is not able to provide any orientation envisions a very complex world, and a cognitive map where causal links have a structure envisions a world of intermediate complexity.
This approach to complexity is useful in order to explain sudden jumps in decision-making, from an established course of action to realizing of the importance of breaking from that established course when novel events interrupt our certitudes, requiring a novel vision of what are the right things to do. Changing one’s vision corresponds to changing one’s cognitive map, either as a consequence of losing faith in an established one or because of restored confidence in a new one (Sigismund-Huff & Huff, 2000).
Organizations may take a long time in order to realize that their cognitive frame should be changed, and they may take an even longer time in order to change it. Evidence suggests that changing a cognitive map is not triggered automatically by a single instance of an unexpected reaction of competitors, or by other changes in the environment. Organizations go through phases of shock and defensive retreat; continue doing the same, but more; wanting to “weather the storm” before acknowledging changes and adapting to the new reality by “unlearning yesterday” and “inventing tomorrow” (Fink, et al., 1971; Hedberg, et al., 1976; see also Ford, 1985; Ford & Baucus, 1987; Mone, et al., 1998). For instance, the first reaction of the US automotive industry to the entrance of Japanese rivals in the US market was to blame its difficulties “on the government, on unfair trade, on brick-headed workers, on snooty American consumers, and (...) on the ‘congenital sickos’ in the media” (Ingrassia & White, 1994: 456; see also Womack, et al., 1990). Only after years of irregular and dwindling profits was it realized that Detroit’s view of a reasonably predictable world and competitive advantages built on economies of scale had given way.
Realizing that one’s cognitive map is not providing the right guidelines is the stimulus that triggers a search for a new one. Recognizing the inadequacy of a cognitive map to deal with novel phenomena, stopping decision-making in order to formulate a new cognitive map and starting again as soon as it has become available, is a continuous, never ending process.
On the one hand, a cognitive map makes sense as far as it is able to provide simple and reliable guidance to decision-making. Being simple, in the sense of providing clear-cut directions of causality, is part of the very nature of a cognitive map (Axelrod, 1976). On the other hand, simplicity and coarseness make a cognitive map obsolete when novelties appear. When the causal links that a cognitive map proposes in order to interpret reality are at odds with real experiences, then a decision-maker has a complicated, intertwined map, one that says that for as a consequence of any option anything may happen. Such a cognitive map is useless. When managers do not know what to do - when they prefer waiting to acting - then they would say that the situation is complex. It is wiser to wait and see, postponing decision-making until a new, reliable cognitive map has become available. It is the source of liquidity preference in the face of too uncertain investment prospects (Keynes, 1936).
A cognitive map that is able to provide a sensible orientation in decision-making is a simple one, one that connects options to objectives with a few, clear-cut causal links. Novelties may emerge, that eventually generate additional causal relationships. This means that it becomes very difficult for managers to make a decision, since they foresee many different, even opposite outcomes for each single option. Decisions are likely not to be made until a new cognitive map has been developed. Clearly, we cannot predict the new map that will be conceived, but we can measure the extent to which the present one is far from being simple, and call this magnitude complexity.
Complexity, as it has been expounded in this section, denotes a mismatch between the world as it is envisioned by decision-makers and reality as it actually is. A basic tenet of organization theory is that an organization’s information processing capacity should be tailored to the information processing requirements of its environment (Tushman & Nadler, 1978). This is not the case when an organization views its environment as complex.
...And what a decision-maker should know
In the previous section complexity is defined in terms of key managers lacking confidence in the cognitive map that they had been using hitherto. Sooner or later action should be taken in order to solve this problem. As we shall see, this observation suggests a second and complementary view of complexity.
Through collection of new data, brainstorming and discussion, managers sooner or later will be able to construct a cognitive map that provides an explanation for confusing facts. It is not our purpose to describe the creative aspects of the process by which a novel cognitive map is formulated. Rather, we pick the point in time when a novel cognitive map has just been conceived and we focus on its implementation. Once a new cognitive map is there, managers face well-defined organizational problems in search for relevant information.
Supposing that a just-forged cognitive map must be applied to concrete situations, one can think of organizational complexity as of the amount of information that is necessary in order to solve a given class of decision problems. One can think of a collection of tasks, employees, or structural features that can be arranged in different ways in order to perform adequately in the situations that are envisaged by the accepted cognitive map. For the purpose of this paper, organizational structure refers to the assignment of tasks and authority to employees; to the grouping of these employees in organizational units and other work relationships; and to the connections between these units and their overall arrangement. The goal is to attain a good fit between the elements that make up an organizational structure and its environment.
An organization will need information about certain characteristics of its tasks, its employees and its own structural features in order to fit its employees with the tasks they face in particular organizational positions. However, the required information on the specific abilities of single employees may well depend on the many possible ways of arranging these employees. Moreover, information produced by individual employees who are dispersed throughout the organization will have to be aggregated in one of many possible ways in order to be useful to top managers. Thus, the amount of information that is required, and the number of employees that should be consulted in order to solve a decision problem, is likely to be affected by organizational structure. Two examples illustrate these points.
Example 1: In a production process where various tasks must be performed sequentially, inventories reduce the amount of information on the timing of individual tasks that is required to run the overall process smoothly. On the contrary, Just-in-Time production systems require transmission of detailed information between production units (kanban), but also that managers have detailed knowledge of the features of each production unit. In fact, to the extent that production units cannot be made as flexible as to perform any task and process lots of any size, the set of possible sequencing paths has to be planned by management in much greater detail than in the case inventories are there to buffer mistakes and suboptimal arrangements. Thus, the particular decision problem of managing production can be solved by organizational arrangements that choose different combinations of the amount of inventories and the amount of information needed to eliminate inventories. This is akin to Galbraith’s (1973: 14-19) account of the effects of, on the one hand, the introduction of slack resources on the need for information processing and, on the other hand, the creation of lateral relations on the capacity to process information. Example 2: According to Alfred Chandler, (1962), the main reason the functional form gave way to the multi-divisional form was that the latter structure solved two problems the former created: information overload at the top management level, and lack of information on product line profitability. Relevant information on product profitability could actually be produced by functional structures, but only at a very high cost since it had to be pulled out of many functions. On the contrary, within a multi-divisional structure such information is readily generated as part of the financial information on which divisional managers base their decisions. Ultimately, the multi-divisional structure allowed to solve decision problems related to product lines by means of less information, because it only produced the needed one.
In general, since employees differ from one another with respect to the ability by which they perform a specific task, their assignment to positions in an organizational structure is likely to determine its overall performance. However, correct assignment of employees requires information on their specific abilities, generally in varying degrees of detail depending on organizational structure. Therefore, the amount of information on the abilities of employees that is required by an organizational designer in order to solve his assignment problem induces an ordering of organizational structures. This amount of information can be used as a measure of organizational complexity.
To show how one could operationalize such an approach, consider the problem of a firm that contemplates the introduction of a new product. As it is unclear whether this product will be good (g) and give rise to a profit, X, or bad (b) and lead to a loss, -Y, different departments of the firm run a number of tests, t. There is an a priori probability of a of a product being good. All tests are imperfect in that bad products may pass a test favorably (A or Accept), while good products may receive a negative verdict (R or Reject). That is, a test t can be de scribe d by the pair
The firm then faces the twin problems of (a) determining for every structure which department should first run a test, which next, and (b) which of the structures to use. As the purpose of this example is to illustrate the use of a cognitive notion of complexity we focus on the first question - the second question, and the interplay of performance with complexity and robustness, is addressed in Visser, (2002). The formal proofs for the statements made in this section can be found in Appendix B.
The complexity of this decision problem is measured by the level of detail of information about the individual tests that is necessary and sufficient to determine the optimal ordering. It can be shown that it is not so much the number of tests, but rather the way in which tests are run consecutively by the departments that determines the kind of information that the firm needs to possess about the qualities of the test in order to position them correctly.
If departments are organized in a simple sequence like the ones depicted in Figures 4 (a) and (e), where a department runs a test only if preceding departments have either all accepted or all rejected the product, no information about the qualities of individual tests is required to attain the best performance. This is easy to see for the sequence of Figure 4(a), as the probability of final implementation is simply the product of acceptance of individual tests,
If, however, departments are arranged like in Figures 4 (b) and (d), with alternating connections between departments, but where any test can still be final, profit maximization requires the firm to be able to order tests in terms of their characteristics as the best test should be used first. That is, the firm needs ordinal information about the quality of the tests run by its departments. If tests cannot be ordered using the ‘better’ criterion because, say, a test t run by a department has a higher probability of accepting both good and bad projects than some other test t', the firm needs cardinal information, i.e., information about the numerical values of the characteristics of the tests.
Finally, in structures like the one depicted in Figure 4 - where at least one test t is always followed by some other test t', irrespective of the outcome of test, t - cardinal information is required. That is, the firm needs not only to be able to order the tests in terms of their characteristics, but also to know the precise probabilities of acceptance. Clearly, by moving from the structures depicted in Figures 4 (a) and (e) through those in Figures 4 (b) and (d) to the one in Figure 4 (c), the firm’s problem becomes more complex since cardinal information is more detailed than ordinal information.
Figure 4 Five structures
Once an ordinal/cardinal distinction has been made, the amount of information required to solve an organizational problem can be measured in terms of number of items to be measured. Within structures that require, say, ordinal information, one may usefully distinguish between numbers of tests to be ordered. Recall that in Figures 4 (b) and (d) one only needed to be able to identify the best test. That is, one had to be able to distinguish two specific groups of tests: the best test, and the others. In larger structures that have different connections between successive desks, like the ones depicted in Figures 4 (b) and (d), the number of groups of tests that one should be able to identify can easily grow. Although ordinal information is still sufficient, the increase in the number of groups that one needs to identify does imply a correspondingly harder task for the firm. In this sense, the size of the organization affects the difficulty of the organizational design problem. In other words, one could think of the type of connections to induce a qualitative classification of required information, and the size of the organization as inducing a quantitative refinement of that classification.
Among those who approached organizational complexity as a characteristic of the structure of an organization there is wide agreement that this characteristic is in fact objectively given and that it captures differences among organizational units, but there is little agreement regarding the details. This comes clearly to the fore when discussing degrees of complexity and operational measures of it. Both Thompson and Galbraith emphasize relationships between units, not their mere number, as a measure of complexity. For instance, Thompson (1967: 74) claims that “size alone does not result in complexity”. Also for Scott, (2002) organizational complexity has to be identified with the type of relationships among organizational parts. The contrast with, e.g., Jablin, (1987) and Daft, (1989), could hardly be starker: they express horizontal and vertical complexity in terms of numbers of units and layers, respectively.
We claim that this issue can be addressed within the framework developed above. As in Thompson and Galbraith, it is the type of relationships between successive units that determines complexity when this is measured in terms of the organizational designer needing ordinal or cardinal information in order to arrange the parts. As in Jablin, it is the size of an organization that determines complexity when this is measured in terms of its designer needing information on a number of tests in order to arrange them. If we stipulate that any amount of cardinal complexity is larger than any amount of ordinal complexity, these two measures do not contradict one another.
Clearly, we have presented a very stylized model. However, one could conceivably expand the above scheme to tests or agents that classify projects on the basis of higher dimension categories, providing judgements richer than a simple accept/reject dichotomy. In the case of decision makers, the combination of individual mental categories would yield a cognitive map of the kind illustrated in Figure 1, which would explicitly depend on organizational structure.
Concluding remarks
The two approaches presented above are distinct yet not opposite to one another. In fact, in section “What a decision-maker does not know...” we defined complexity in terms of inadequacy of what is currently known in order to solve an ill-defined problem. Subsequently, in section “...and what a decision-maker should know” we defined complexity in terms of what should be known in order to solve a well-defined problem. In between, the task of transforming ill-defined problems into well-defined problems by means of the new interpretation provided by a novel cognitive map, was left unspecified. However, in spite of a missing link the above approaches are complementary in the sense that the first one aims at assessing improper framing of decision problems, whereas the second one attempts to provide operative solutions once problems have been reframed.
These perspectives are not independent of one another, because problem framing depends on organizational structure. Consider that the cognitive map of an organization is the result of organizational interpretation and information processing with a view to building causal relationships needed to guide decision-making. Both interpretation and information processing are intimately tight up with organizational structure. It determines how information is aggregated, coded and classified; it influences the options considered and the criteria used in such considerations by decision makers throughout the organization; and it regulates how and which conflicts over interpretation, decision, and implementation are referred to higher levels for resolution, thereby affecting in turn what is being learned by whom (Hammond, 1994). This is likely to strongly affect the organizational view on causation, on the relationships between the options open to the organization on the one hand, and the envisioned outcomes on the other hand; in short, on the cognitive map.
This also suggests that the relationship between the two concepts of complexity is perhaps not as simple as depicted above. Hammond’s analysis directs attention to the convoluted nature of this relationship, with the organizational structure influencing the cognitive map, and the cognitive map influencing the search for an adequate structure in its turn.
Appendix A
This appendix expounds the mathematics for measuring complexity as it has been defined in section “What a decision-maker does not know...” It is based on a seminal work by Robert Atkin (1974, 1981), subsequently adapted to cognitive maps (Fioretti ,1998, 1999).
Let A = {Ai} and B = {Bi} denote the options and the objectives envisaged by managers, respectively. Let Bi denote the subset of objectives that are connected to option Ai, with i = 1,2,...n.
A simplicial complex can be used in order to represent the connections between options and objectives. It is composed of as many simplices as the number of options and as many vertices as the number of objectives. For instance, the vertices of simplex Ai are the elements of Bi.
If empirical experience confirms a cognitive map, i.e. if the correspondences between options and objectives are all one-to-one, simplices are isolated points and no simplicial complex exists: complexity is zero. On the contrary, if at least two simplices have at least one vertex in common, a simplicial complex arises: complexity is greater than zero.
Let us define an incidence matrix Λ of dimensions n×n, whose generic element lij takes the values:
λij= 1 if Bi ϵ Bi , 0 otherwise
Element (i,j) of matrix ΛΛT is the number of vertices that simplices Ai and Aj have in common. Thus, element lij of matrix Λ= ΛΛT-11T is the dimension of the eventual common face between simplices Ai~~ and Aj. If this number is negative, simplices Ai and Aj have no common vertex.
Two simplices that have no vertex in common may nonetheless be connected by a chain of simplices having common vertices with one another. Let us say that simplices Ai and Aj are q-connected if there exists a chain of simplices {Au,Av,...Aw} such that q:= min {liu,luv,...lwj} is not less than zero. In particular, two contiguous simplices are connected at level q if they have a common face of dimension q.
Let us consider common faces between simplices and let us focus on the face of largest dimension: let Q denote the dimension of this face. Note that Q is not necessarily the largest possible dimension of a common face: given n objectives, the largest possible dimension of a common face is n-1 and this only occurs when two simplices of dimension n-1 coincide.
By inspection of matrix L we can partition the set of simplices that compose the simplicial complex according to connection level q. Let us introduce a structure vector s of dimensions (Q+ 1) ×1, and let us denote its q-th component by sq. In general, for any connection level q there exist classes of simplices such that the simplices belonging to a class are connected at that level. Let the q-th component of structure vector s denote the number of disjoint classes of simplices that are connected at level q.
In order to avoid repetitions in the calculus of complexity, we do not consider a class of simplices connected at level q to be also a class of simplices connected at levels q - 1, q - 2, etc. For example, let simplices A1 and A2 be connected at level q = 2, and let simplex A3 be connected with A2 at level q = 1. Then, {A1, A2} is a class of simplices connected at q = 2 and {A1,A2,A3} is a class of simplices connected at q = 1. However, {A1, A2} is not a class of simplices connected at level q = 0.
Once structure vector is available, complexity can be measured as:
where the sum extends only to the terms such that sq <> 0. Finally, it is stipulated that the complexity of two or more disconnected simplicial complexes is the sum of their complexities.
Appendix B
In this appendix a formal proof is given of the relationship between the level of detail of information that is necessary and sufficient to establish the correct order of departments running tests, and the type of organizational structure. It was already shown in the text that the structures depicted in Figures 4 (a) and (e) do not require any knowledge about the qualities of the individual tests. We will therefore limit ourselves to the remaining structures as represented by Figures 4 (b), (c), and (d). Note that the expected profit on implemented projects equals αXpg(Org) - (1-α)Ypb(Org), where pq (Org) stands for the probability with which a particular arrangement of departments accepts a project of quality q ∊ {g,b}.
Consider the arrangement of departments as depicted in Figure 4 (b). Here,
Clearly, changing the order of tests t2 and t3 leaves the probability of acceptance unaffected. Now assume the tests can be ordered using the ‘better’ criterion, and that t1 is better than t2, which is better than t3. It is easy to see that the department that runs the first test should be the best, as the department that runs it can make a final decision on its own. Changing the order of tests t1 and, say, t2, leads to change in the probability of acceptance equal to
This difference is positive for good projects and negative for bad projects, implying an unequivocal worsening of the composition of accepted projects, leading to reduction in expected profits. When tests are ordered using the ‘better’ criterion, the organizational designer needs to be able to identify the best test: ordinal information is required (and sufficient) to correctly assign departments to positions in the organizational structure. Clearly, if the tests are not ordered using the ‘better’ criterion, information about the exact probabilities of acceptance are necessary, as the direction of change of expected profit can no longer be established unequivocally.
The same line of reasoning applies to the structure depicted in Figure 4 (d): if tests can be ordered using the ‘better’ criterion, then ordinal information is necessary and sufficient to determine the order in which departments should run tests. The first test to be run should be the best. The order of the second and the third is immaterial. If tests cannot be ordered using the ‘better’ criterion, cardinal information is necessary to correctly assign the departments to organizational positions.
Finally, the structure depicted in Figure 4 (c) requires cardinal information, even if the individual tests can be ordered using the ‘better’ criterion. The probability of acceptance of a project of quality q equals,
Switching the position of department 3 and 1 changes the probability of acceptance:
If tests can be ordered using the ‘better’ criterion, equation (1) is positive for good projects, and negative for bad ones, implying t3 and t1 should not be switched. Similarly, tests t3 and t2 should not be switched. Note that ordinal information is sufficient to ascertain the correctness of these assignments. However, knowing whether t1 and t2 are correctly assigned required cardinal information. Switching the departments that run these tests gives rise to a change in probability equal to,
Although and
References
Allen, P. M. (2000) “Knowledge, ignorance, and learning, Emergence,” 2(4): 78-103.
Allen, P. M. (2001). “What is complexity science? Knowledge of the limits to knowledge,” Emergence, 3(1): 24-42.
Allen, P. M. and Strathern, M. (2003). “Evolution, emergence, and learning in complex systems,” Emergence, 5(4): 8-33.
Anderson, P. (1999). “Complexity theory and organization science,” Organization Science, 10: 216-232.
Anderson, P. and Paine, F. T. (1975). “Managerial perceptions and strategic behavior,” Academy of Management Journal, 18: 811-823.
Atkin, R. (1974). Mathematical structures in human affairs, New York, NY: Crane, Russak and Company.
Atkin, R. (1981) Multidimensional man, Harmondsworth: Penguin Books.
Axelrod, R. (1976). Structure of decision: The cognitive maps of political elites, Princeton: Princeton University Press.
Chaitin, G. J. (1966). “On the length of programs for computing finite binary sequences,” Journal of the Association for Computing Machinery, 13: 547-69.
Chandler, A. (1962). Strategy and structure. Chapters in the history of the industrial enterprise, Cambridge, MA: MIT Press.
Cilliers, P. (2002). “Why we cannot know complex things completely,” Emergence, 4(1/2): 77-84.
Crutchfield, J. P. and Young, K. (1989). “Inferring statistical complexity,” Physical Review Letters, 63: 105-8.
Daft, R. L. (1989). Organization theory and design, St. Paul: West Publishing Company.
Dupuy, J. P. (1982). Ordres et désordres, Paris: Editions du Seuil.
Fink, S., Beak, J. and Taddeo, K. (1971). “Organizational crisis and change,” Journal of Applied Behavioral Science 7 :15-27.
Fioretti, G. (1998). “A concept of complexity for the social sciences,” R’evue Inter-nationale de Syst’emique, 12: 285-312.
Fioretti, G. (1999). “A subjective measure of complexity,” Advances in Complex Systems, 4: 349-70.
Fontana, W. (1991). “Algorithmic chemistry,” in C. G.
Langton, C. Taylor, J. D. Farmer and S. Rasmussen (eds.), Artificial Life II : Proceedings of the Workshop on Artificial Life Held February, 1990 in Santa Fe, New Mexico (Santa Fe Institute Studies in the Sciences of Complexity Proceedings), Redwood City: Addison-Wesley, pp. 159-209.
Ford, J. D. (1985). “The effects of causal attributions on decision makers’ responses to performance downturns,” Academy of Management Review, 10: 770-786.
Ford, J. D. and Baucus, D. A. (1987).” Organizational adaptation to performance downturns: An interpretation- based perspective,” Academy of Management Review, 12: 366-380.
Frank, K. A. and Fahrbach, K. (1999). “Organization culture as a complex system: Balance and information in models of influence and selection,” Organization Science, 10(3): 253-277.
Galbraith, J. (1973). Designing complex organizations, Reading, MA: Addison-Wesley.
Gell-Mann, M. (1994). The Quark and the Jaguar: Adventures in the simple and the complex, New York, NY: Freeman.
Haken, H. (1983). Synergetics: An introduction, Berlin: Springer-Verlag.
Haken, H. (1987). Advanced synergetics, Berlin: Springer-Verlag.
Hammond, T. H. (1994). “Structure, strategy, and the agenda of the firm,” in R. P. Rumelt, D. E. Schendel and D. J. Teece (eds.), Fundamental issues in strategy, Boston, MA: Harvard Business School Press, pp. 97-154.
von Hayek, F. (1952). The sensory order, London, UK: Routledge & Kegan Paul.
Hebb, D. O. (1949). The organization of behavior, New York, NY: John Wiley & Sons.
Hedberg, B., Nystrom, P. and Starbuck, W. (1976). “Camping on seesaws: Prescriptions for a self-designing organization,” Administrative Science Quarterly, 21: 41-65.
Ingrassia, P. and White, J. B. (1994). Comeback: The fall and rise of the American automobile industry, New York, NY: Simon and Schuster.
Jablin, F. M. (1987). “Formal organization structure,” in F. M. Jablin, L. L. Putnam, K. Roberts and L. Porter (eds.), Handbook of organizational communication. An interdisciplinary perspective, Newbury Park: Sage Publications, pp. 389-419.
Kauffman, S. (1993). The origins of order, Oxford, UK: Oxford University Press.
Keynes, J. M. (1936). The general theory of employment, interest and money, London, UK: MacMillan, reprinted in 1973, The collected writings of J. M. Keynes, vol. VII.
Kolmogorov, A. N. (1965). “Three approaches to the quantitative definition of information, problems of information transmission,” 1: 1-7, reprinted in 1968, International Journal of Computer Mathematics, 2: 157-68.
Lawrence, P. R. and Lorsch, J. W. (1967). “Differentiation and integration in complex organizations,” Administrative Science Quarterly, 12: 1-30.
Lissack, M. R. (1999a). “Complexity and management: It is more than jargon,” in M. R. Lissack and H. P. Gunz (eds.), Managing complexity in organizations: A view in many directions, Westport, CT: Quorum Books, pp. 11-28.
Lissack, M. R. (1999b). “Complexity: The science, its vocabulary, and its relation to organizations”, Emergence, 1(1): 110-126.
Lissack, M. R. and Letiche, H. (2002). “Complexity, emergence, resilience, and coherence: Gaining perspective on organizations and their study,” Emergence, 4(3): 72-94.
Marion, R. (1999). The edge of organization: Chaos and complexity theories of formal social systems, Thousand Oaks: SAGE Publications.
Mone, M. A., McKinley, W. and Barker III, V. L. (1998). “Organizational decline and innovation: A contingency framework,” Academy of Management Review, 23:115-132.
Morel, B. and Ramanujam, R. (1999). “Through the looking glass of complexity: The dynamics of organizations as adaptive and evolving systems,” Organization Science, 10(3): 278-293.
Nicolis, G. and Prigogine, I. (1977). Self-organization in non-equilibrium systems: From dissipative structures to order through fluctuations, New York, NY: John Wiley & Sons.
Prigogine, I. and Prigogine, G. (1989). Exploring complexity: An introduction, New York, NY: Freeman & Co.
Rescher, N. (1998). Complexity: A philosophical overview, New Brunswick, NJ: Transaction.
Rosen, R. (1985). Anticipatory systems, Oxford, UK: Pergamon Press.
Sah, R. K. and Stiglitz, J. E. (1986). “The architecture of economic systems: Hierarchies and polyarchies,” American Economic Review, 76: 716-727.
Scott, W. R. (2002). Organizations: Rational, natural and open systems, 5th edition, Upper Saddle River, NJ: Prentice Hall.
Sigismund-Huff, A. (1990). “Mapping strategic thought,” in A. Sigismund-Huff (ed.), Mapping strategic thought, Chichester, UK: John Wiley & Sons, pp. 11-49.
Sigismund-Huff, A. and Huff, J. O. (2000). When firms change direction (with P. Barr), Oxford, UK: Oxford University Press.
Sigismund-Huff, A. and Schwenk, C. R. (1990). “Bias and sensemaking in good times and bad,” in A. Sigismund- Huff (ed.), Mapping strategic thought, Chichester, UK: John Wiley & Sons, pp. 89-108.
Simon, H. A. (1999). The sciences of the artificial, 3rd edition, Cambridge, MA: The MIT Press.
Sobek II, D. K., Liker, J. K. and Ward, A. C. (1998). “Another look at how Toyota integrates product development,” Harvard Business Review, 76: 36-49.
Solomonoff, R. J. (1964). A formal theory of inductive inference, information and control, 7: 1-22, 224-54.
Thompson, J. D. (1967). Organizations in action: Social science bases of administrative theory, New York, NY: McGraw- Hill Book Company.
Tushman, M. L. and Nadler, D. A. (1978). “Information processing as an integrating concept in organizational design,” Academy of Management Review, 3: 613-624.
Visser, B. (2001). Classifying organizations of boundedly rational agents, Mimeo: Erasmus University Rotterdam.
Visser, B. (2002). “Complexity, robustness, performance: Trade-offs in organizational design,” Tinbergen Institute discussion paper.
Womack, J. P., Jones, D. T. and Roos, D. (1990). The machine that changed the world, New York, NY: Rawson Associates.